
This blog will teach you how to use Keras and TensorFlow to work with text and recurrent neural networks. You will learn the theory and practice of RNNs and how to apply them to sentiment analysis, text generation and machine translation tasks.
1. Introduction
Welcome to this blog on Keras and TensorFlow Mastery: Working with Text and Recurrent Neural Networks. In this blog, you will learn how to use Keras and TensorFlow to work with text and recurrent neural networks (RNNs). You will learn the theory and practice of RNNs and how to apply them to sentiment analysis, text generation and machine translation tasks.
But first, what are Keras and TensorFlow? And why are they useful for working with text and RNNs?
Keras is a high-level neural network API that allows you to easily build, train and evaluate deep learning models. It runs on top of TensorFlow, which is a low-level framework that provides the core operations and functionalities for building and running neural networks. Keras and TensorFlow are both open-source and widely used in the machine learning community.
One of the advantages of using Keras and TensorFlow is that they offer a variety of tools and modules for working with text and RNNs. For example, you can use the tf.data API to load and preprocess text data, the tf.keras.layers module to create different types of RNN layers, and the tf.keras.models module to define and train your RNN models. You can also use the tf.keras.callbacks module to monitor and save your model’s performance, and the tf.keras.utils module to generate text from your trained models.
By using Keras and TensorFlow, you can simplify and streamline the process of working with text and RNNs, and focus on the core logic and creativity of your tasks.
So, are you ready to dive into the world of text and RNNs with Keras and TensorFlow? Let’s get started!
2. What are Recurrent Neural Networks?
In this section, you will learn what recurrent neural networks (RNNs) are and why they are useful for working with text. You will also learn about the different types of RNN cells and how they work.
But first, what is a neural network? And what is a text?
A neural network is a computational model that consists of a series of interconnected units called neurons. Each neuron can receive inputs from other neurons, perform some calculation, and produce an output. The output of one neuron can be the input of another neuron, forming a network of connections. A neural network can learn from data by adjusting the weights of the connections based on the error between the predicted output and the actual output.
A text is a sequence of symbols, such as words, characters, or tokens, that convey some meaning. A text can be a sentence, a paragraph, a document, or any other unit of natural language. A text can be represented as a vector of numerical values, such as one-hot encoding, word embedding, or character embedding.
So, what is a recurrent neural network? And why is it suitable for text processing?
A recurrent neural network (RNN) is a type of neural network that can process sequential data, such as text. Unlike a regular neural network, which assumes that the inputs are independent of each other, an RNN can maintain a hidden state that stores the information from the previous inputs. This way, an RNN can capture the temporal dependencies and the context of the sequence.
For example, suppose you want to predict the next word in a sentence, such as “The sky is ___”. A regular neural network would treat each word as an independent input, and would not be able to use the information from the previous words. An RNN, on the other hand, would use the hidden state to remember what the previous words were, and use that information to make a better prediction.
Therefore, RNNs are useful for text processing tasks, such as sentiment analysis, text generation, and machine translation, where the meaning and the structure of the text depend on the order and the context of the words.
However, not all RNNs are the same. There are different types of RNN cells that have different architectures and functionalities. In the next subsections, you will learn about three common types of RNN cells: the basic RNN cell, the long short-term memory (LSTM) cell, and the gated recurrent unit (GRU) cell.
2.1. The Basic RNN Cell
The basic RNN cell is the simplest type of RNN cell. It consists of a single layer of neurons that takes the current input and the previous hidden state as inputs, and produces the new hidden state as output. The hidden state is then passed to the next time step, forming a loop.
The basic RNN cell can be represented by the following equation:
$$h_t = \tanh(W_{xh}x_t + W_{hh}h_{t-1} + b_h)$$
where $h_t$ is the hidden state at time step $t$, $x_t$ is the input at time step $t$, $W_{xh}$ and $W_{hh}$ are the weight matrices, and $b_h$ is the bias vector. The $\tanh$ function is the activation function that squashes the output between -1 and 1.
The basic RNN cell can be implemented in Keras and TensorFlow using the tf.keras.layers.SimpleRNN layer. This layer takes the input sequence and returns either the full sequence of hidden states or the last hidden state. You can specify the number of neurons, the activation function, and other parameters of the layer.
For example, the following code creates a basic RNN layer with 32 neurons and a tanh activation function:
from tensorflow.keras.layers import SimpleRNN
rnn_layer = SimpleRNN(units=32, activation='tanh')
The basic RNN cell is easy to understand and implement, but it has some limitations. One of the main limitations is the vanishing gradient problem, which means that the gradients of the error function tend to become very small or zero as they propagate back through time. This makes it difficult for the basic RNN cell to learn long-term dependencies and capture the context of the sequence.
To overcome this problem, more advanced types of RNN cells have been developed, such as the long short-term memory (LSTM) cell and the gated recurrent unit (GRU) cell. In the next subsections, you will learn how these cells work and how to use them in Keras and TensorFlow.
2.2. The Long Short-Term Memory (LSTM) Cell
The long short-term memory (LSTM) cell is a type of RNN cell that can overcome the vanishing gradient problem and learn long-term dependencies. It does so by introducing a memory cell that can store and manipulate information over time. The memory cell is controlled by three gates that regulate the flow of information: the input gate, the forget gate, and the output gate.
The LSTM cell can be represented by the following equations:
$$f_t = \sigma(W_{xf}x_t + W_{hf}h_{t-1} + b_f)$$
$$i_t = \sigma(W_{xi}x_t + W_{hi}h_{t-1} + b_i)$$
$$o_t = \sigma(W_{xo}x_t + W_{ho}h_{t-1} + b_o)$$
$$\tilde{c}_t = \tanh(W_{xc}x_t + W_{hc}h_{t-1} + b_c)$$
$$c_t = f_t \odot c_{t-1} + i_t \odot \tilde{c}_t$$
$$h_t = o_t \odot \tanh(c_t)$$
where $f_t$, $i_t$, and $o_t$ are the forget gate, the input gate, and the output gate at time step $t$, respectively. $\sigma$ is the sigmoid function that squashes the output between 0 and 1. $\odot$ is the element-wise multiplication. $c_t$ is the memory cell at time step $t$. $\tilde{c}_t$ is the candidate memory cell at time step $t$. $h_t$ is the hidden state at time step $t$. $x_t$ is the input at time step $t$. $W_{xf}$, $W_{xi}$, $W_{xo}$, $W_{xc}$, $W_{hf}$, $W_{hi}$, $W_{ho}$, and $W_{hc}$ are the weight matrices. $b_f$, $b_i$, $b_o$, and $b_c$ are the bias vectors.
The LSTM cell can also be visualized by the following diagram:
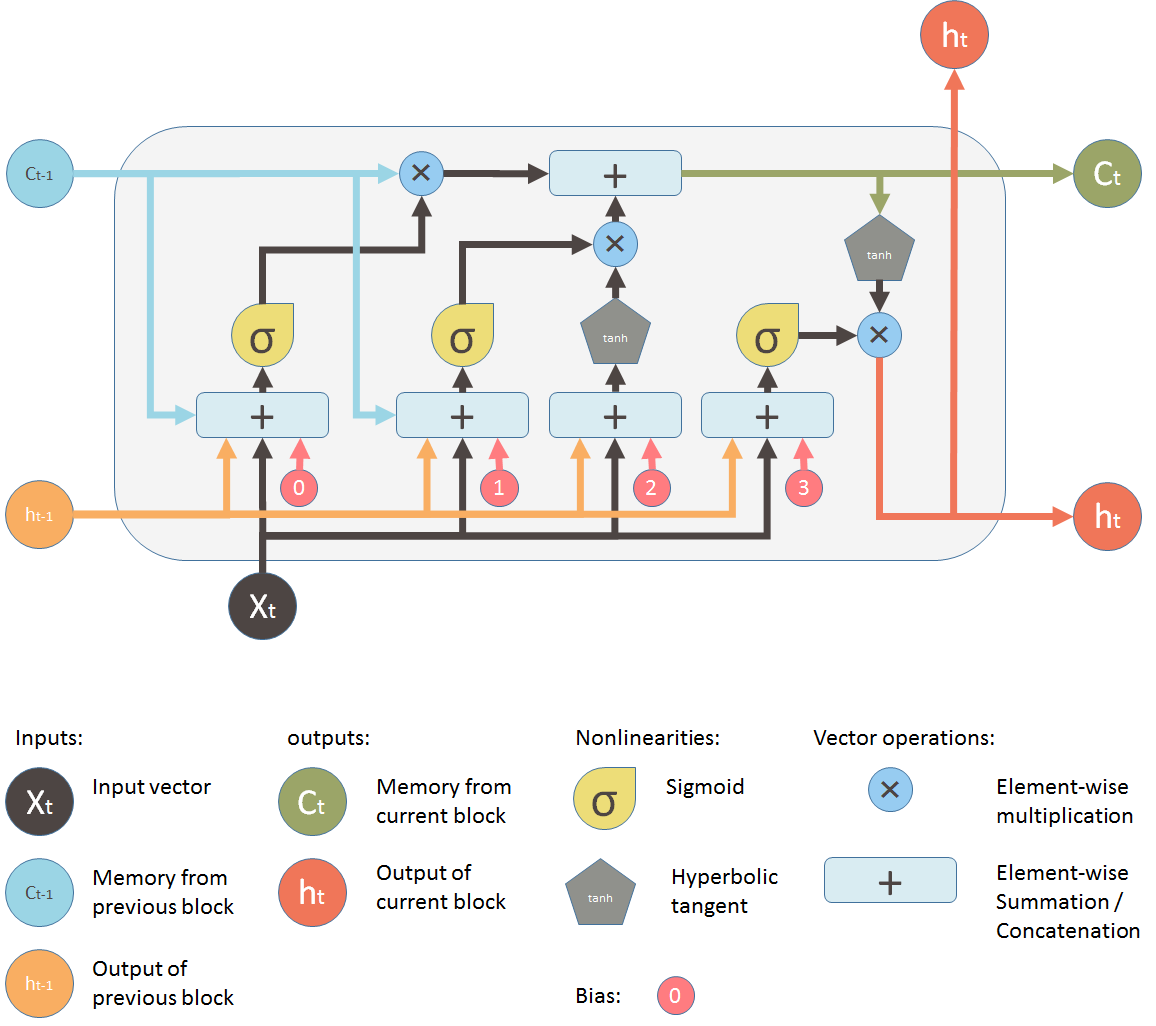
Source: https://towardsdatascience.com/understanding-lstm-and-its-diagrams-37e2f46f1714
The LSTM cell can be implemented in Keras and TensorFlow using the tf.keras.layers.LSTM layer. This layer takes the input sequence and returns either the full sequence of hidden states or the last hidden state. You can specify the number of neurons, the activation function, and other parameters of the layer.
For example, the following code creates an LSTM layer with 32 neurons and a tanh activation function:
from tensorflow.keras.layers import LSTM
lstm_layer = LSTM(units=32, activation='tanh')
The LSTM cell is more powerful and complex than the basic RNN cell, but it also has some drawbacks. One of the drawbacks is that it has more parameters to learn, which can increase the computational cost and the risk of overfitting. Another drawback is that it can suffer from the exploding gradient problem, which means that the gradients of the error function tend to become very large or infinite as they propagate back through time. This can cause the weights to diverge and the model to become unstable.
To address these drawbacks, another type of RNN cell has been proposed, called the gated recurrent unit (GRU) cell. In the next subsection, you will learn how the GRU cell works and how to use it in Keras and TensorFlow.
2.3. The Gated Recurrent Unit (GRU) Cell
The gated recurrent unit (GRU) cell is a type of RNN cell that is similar to the LSTM cell, but simpler and more efficient. It also introduces a memory cell that can store and manipulate information over time, but it uses only two gates instead of three: the reset gate and the update gate.
The GRU cell can be represented by the following equations:
$$r_t = \sigma(W_{xr}x_t + W_{hr}h_{t-1} + b_r)$$
$$z_t = \sigma(W_{xz}x_t + W_{hz}h_{t-1} + b_z)$$
$$\tilde{h}_t = \tanh(W_{xh}x_t + W_{hh}(r_t \odot h_{t-1}) + b_h)$$
$$h_t = (1 – z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t$$
where $r_t$ and $z_t$ are the reset gate and the update gate at time step $t$, respectively. $\sigma$ is the sigmoid function that squashes the output between 0 and 1. $\odot$ is the element-wise multiplication. $\tilde{h}_t$ is the candidate hidden state at time step $t$. $h_t$ is the hidden state at time step $t$. $x_t$ is the input at time step $t$. $W_{xr}$, $W_{xz}$, $W_{xh}$, $W_{hr}$, $W_{hz}$, and $W_{hh}$ are the weight matrices. $b_r$, $b_z$, and $b_h$ are the bias vectors.
The GRU cell can also be visualized by the following diagram:
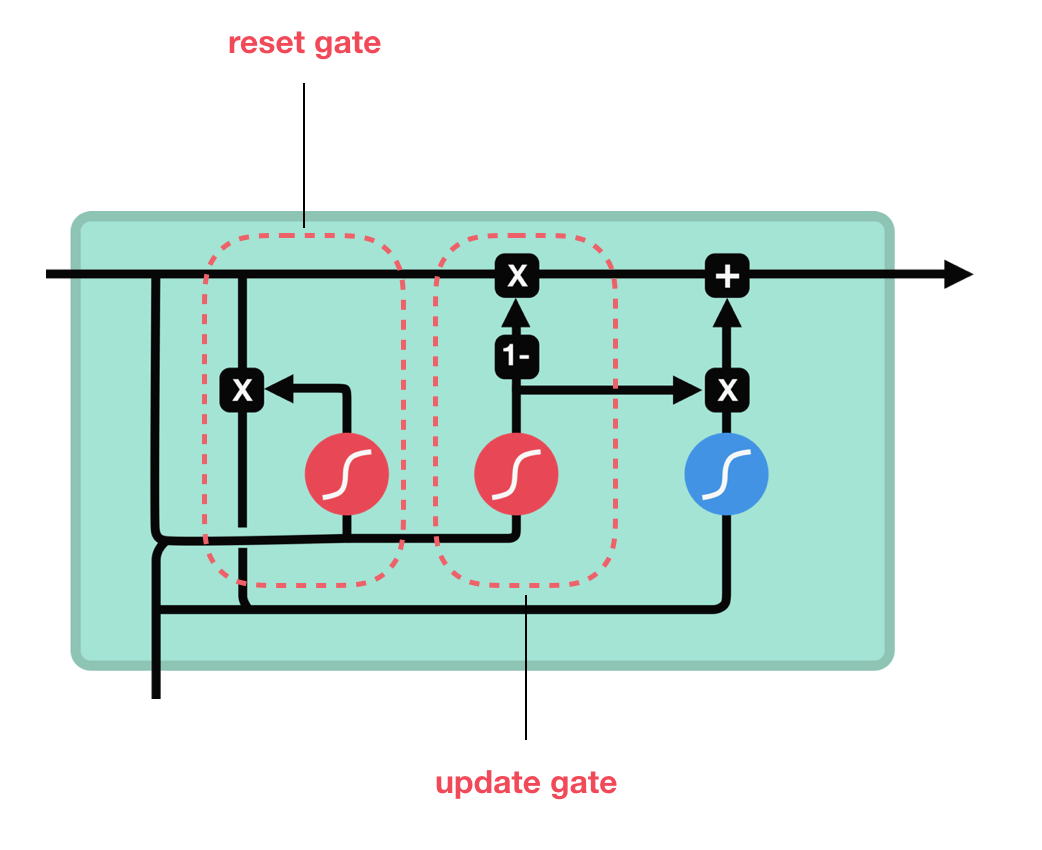
Source: https://towardsdatascience.com/understanding-gru-networks-2ef37df6c9be
The GRU cell can be implemented in Keras and TensorFlow using the tf.keras.layers.GRU layer. This layer takes the input sequence and returns either the full sequence of hidden states or the last hidden state. You can specify the number of neurons, the activation function, and other parameters of the layer.
For example, the following code creates a GRU layer with 32 neurons and a tanh activation function:
from tensorflow.keras.layers import GRU
gru_layer = GRU(units=32, activation='tanh')
The GRU cell is a simpler and faster alternative to the LSTM cell, but it can achieve comparable or even better performance on some tasks. However, there is no definitive answer to which type of RNN cell is better, as it depends on the data, the task, and the model architecture. Therefore, it is advisable to experiment with different types of RNN cells and compare their results.
In the next section, you will learn how to use Keras and TensorFlow to build and train RNN models using different types of RNN cells.
3. How to Use Keras and TensorFlow to Build and Train RNNs
In this section, you will learn how to use Keras and TensorFlow to build and train recurrent neural network (RNN) models using different types of RNN cells. You will follow a general workflow that consists of four main steps: preparing the data, defining the model architecture, compiling and fitting the model, and evaluating and saving the model.
Before you start, you need to install and import the necessary libraries and modules. You can use the following code to do so:
# Install TensorFlow
pip install tensorflow
# Import TensorFlow and Keras
import tensorflow as tf
from tensorflow import keras
# Import other modules
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
Now, let’s go through each step of the workflow and see how to use Keras and TensorFlow to build and train RNNs.
3.1. Preparing the Data
The first step of the workflow is to prepare the data for the RNN model. This involves loading, cleaning, splitting, and encoding the data.
The data you use depends on the task you want to perform with the RNN model. For example, if you want to perform sentiment analysis, you can use a dataset of movie reviews and their labels (positive or negative). If you want to perform text generation, you can use a dataset of text from a specific domain or genre (such as news articles or novels). If you want to perform machine translation, you can use a dataset of parallel sentences in two languages (such as English and French).
For this tutorial, we will use a dataset of movie reviews and their labels from the Internet Movie Database (IMDb). This dataset is available in the tf.keras.datasets module, and it contains 50,000 reviews, split into 25,000 for training and 25,000 for testing. Each review is labeled as either positive (1) or negative (0).
You can use the following code to load the dataset:
# Load the IMDb dataset
from tensorflow.keras.datasets import imdb
# Set the vocabulary size
vocab_size = 10000
# Load the training and testing data
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=vocab_size)
The data is already encoded as a sequence of integers, where each integer represents a word in a dictionary. The dictionary maps words to integers based on their frequency in the dataset, so the most frequent word has the index 1, the second most frequent word has the index 2, and so on. The index 0 is reserved for padding, and the index 9999 is reserved for unknown words.
You can use the following code to decode a review back to text:
# Get the word index dictionary
word_index = imdb.get_word_index()
# Reverse the word index dictionary
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
# Define a function to decode a review
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
# Decode the first review in the training data
decode_review(train_data[0])
The output is:
'? this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert ? is an amazing actor and now the same being director ? father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for ? and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also ? to the two little boy's that played the ? of norman and paul they were just brilliant children are often left out of the ? list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all'
As you can see, the review is a positive one, and it has the label 1. You can also see that some words are replaced by the symbol ?, which means they are either unknown or padding.
Before you feed the data to the RNN model, you need to make sure that the reviews have the same length. You can use the tf.keras.preprocessing.sequence.pad_sequences function to pad or truncate the reviews to a fixed length. You can specify the maximum length, the padding type (pre or post), and the value to use for padding.
For example, the following code pads or truncates the reviews to a length of 256, using 0 as the padding value and adding the padding at the end of the reviews:
# Set the maximum length
max_length = 256
# Pad or truncate the training and testing data
train_data = keras.preprocessing.sequence.pad_sequences(train_data, maxlen=max_length, padding='post', value=0)
test_data = keras.preprocessing.sequence.pad_sequences(test_data, maxlen=max_length, padding='post', value=0)
Now, the data is ready to be used by the RNN model. In the next subsection, you will learn how to define the model architecture using different types of RNN layers.
3.1. Preparing the Data
The first step of the workflow is to prepare the data for the RNN model. This involves loading, cleaning, splitting, and encoding the data.
The data you use depends on the task you want to perform with the RNN model. For example, if you want to perform sentiment analysis, you can use a dataset of movie reviews and their labels (positive or negative). If you want to perform text generation, you can use a dataset of text from a specific domain or genre (such as news articles or novels). If you want to perform machine translation, you can use a dataset of parallel sentences in two languages (such as English and French).
For this tutorial, we will use a dataset of movie reviews and their labels from the Internet Movie Database (IMDb). This dataset is available in the tf.keras.datasets module, and it contains 50,000 reviews, split into 25,000 for training and 25,000 for testing. Each review is labeled as either positive (1) or negative (0).
You can use the following code to load the dataset:
# Load the IMDb dataset
from tensorflow.keras.datasets import imdb
# Set the vocabulary size
vocab_size = 10000
# Load the training and testing data
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=vocab_size)
The data is already encoded as a sequence of integers, where each integer represents a word in a dictionary. The dictionary maps words to integers based on their frequency in the dataset, so the most frequent word has the index 1, the second most frequent word has the index 2, and so on. The index 0 is reserved for padding, and the index 9999 is reserved for unknown words.
You can use the following code to decode a review back to text:
# Get the word index dictionary
word_index = imdb.get_word_index()
# Reverse the word index dictionary
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
# Define a function to decode a review
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
# Decode the first review in the training data
decode_review(train_data[0])
The output is:
'? this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert ? is an amazing actor and now the same being director ? father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for ? and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have3.2. Defining the Model Architecture
In this section, you will learn how to define the model architecture for your RNNs using Keras and TensorFlow. You will learn how to create different types of RNN layers, how to stack them, and how to add other layers such as dense, dropout, and embedding layers.
But first, what is a model architecture? And why is it important for your RNNs?
A model architecture is the design and structure of your neural network. It specifies the number, type, and configuration of the layers, as well as the input and output shapes, the activation functions, and the loss function. A model architecture defines how your neural network will process the data and learn from it.
The model architecture is important for your RNNs because it affects the performance and the results of your text processing tasks. Depending on the type and the complexity of the task, you may need different types of RNN layers, such as basic RNN, LSTM, or GRU. You may also need to stack multiple RNN layers to increase the depth and the capacity of your model. Additionally, you may need to add other layers, such as dense, dropout, or embedding layers, to improve the accuracy, the regularization, or the representation of your text data.
Therefore, choosing the right model architecture for your RNNs is a crucial step in building and training your neural network.
So, how can you define the model architecture for your RNNs using Keras and TensorFlow? Let’s see some examples.
To define the model architecture, you need to use the tf.keras.models.Sequential class, which allows you to create a linear stack of layers. You can pass a list of layer instances to the constructor, or you can use the add method to add layers one by one.
For example, suppose you want to create a simple RNN model with one basic RNN layer and one dense layer. You can do it as follows:
# Import the modules
import tensorflow as tf
from tensorflow.keras import layers
# Define the model architecture
model = tf.keras.models.Sequential([
# Add a basic RNN layer with 64 units and tanh activation
layers.SimpleRNN(64, activation='tanh'),
# Add a dense layer with 1 unit and sigmoid activation
layers.Dense(1, activation='sigmoid')
])
Alternatively, you can use the add method to add layers one by one:
# Import the modules
import tensorflow as tf
from tensorflow.keras import layers
# Define the model architecture
model = tf.keras.models.Sequential()
# Add a basic RNN layer with 64 units and tanh activation
model.add(layers.SimpleRNN(64, activation='tanh'))
# Add a dense layer with 1 unit and sigmoid activation
model.add(layers.Dense(1, activation='sigmoid'))
This model architecture could be suitable for a binary classification task, such as sentiment analysis, where the input is a sequence of text and the output is a single value between 0 and 1, indicating the positive or negative sentiment of the text.
However, if you want to create a more complex RNN model, you may need to use different types of RNN layers, such as LSTM or GRU, and stack them together. You may also need to add other layers, such as dropout or embedding layers, to enhance your model.
For example, suppose you want to create an RNN model with two LSTM layers, a dropout layer, and a dense layer. You can do it as follows:
# Import the modules
import tensorflow as tf
from tensorflow.keras import layers
# Define the model architecture
model = tf.keras.models.Sequential([
# Add an LSTM layer with 128 units and tanh activation, and return the full sequence
layers.LSTM(128, activation='tanh', return_sequences=True),
# Add another LSTM layer with 64 units and tanh activation, and return only the last output
layers.LSTM(64, activation='tanh', return_sequences=False),
# Add a dropout layer with 0.2 dropout rate to prevent overfitting
layers.Dropout(0.2),
# Add a dense layer with 10 units and softmax activation
layers.Dense(10, activation='softmax')
])
This model architecture could be suitable for a multiclass classification task, such as text generation, where the input is a sequence of text and the output is a sequence of probabilities for the next word in the vocabulary.
As you can see, by using Keras and TensorFlow, you can easily define the model architecture for your RNNs, and customize it according to your needs and preferences.
In the next section, you will learn how to compile and fit your model to the data, and how to use callbacks to monitor and save your model’s performance.
3.3. Compiling and Fitting the Model
In this section, you will learn how to compile and fit your model to the data using Keras and TensorFlow. You will learn how to specify the optimizer, the loss function, and the metrics for your model, and how to train your model on the data using batches, epochs, and validation sets.
But first, what is compiling and fitting? And why are they necessary for your RNNs?
Compiling is the process of configuring your model for training. It involves specifying the optimizer, the loss function, and the metrics that you want to use to evaluate your model. The optimizer is the algorithm that updates the weights of your model based on the gradient of the loss function. The loss function is the function that measures how well your model predicts the output compared to the actual output. The metrics are the functions that measure the performance of your model on different aspects, such as accuracy, precision, or recall.
Fitting is the process of training your model on the data. It involves feeding the input and output data to your model, and letting the model learn from the data by adjusting the weights based on the optimizer and the loss function. Fitting also involves specifying the batch size, the number of epochs, and the validation set. The batch size is the number of samples that are processed at once by your model. The number of epochs is the number of times that your model goes through the entire data set. The validation set is a subset of the data that is used to evaluate your model’s performance during training, and to prevent overfitting.
Compiling and fitting are necessary for your RNNs because they allow you to fine-tune your model’s parameters and optimize your model’s performance on the data.
So, how can you compile and fit your model using Keras and TensorFlow? Let’s see some examples.
To compile your model, you need to use the compile method of the tf.keras.models.Sequential class, and pass the optimizer, the loss function, and the metrics as arguments. You can use the built-in optimizers, loss functions, and metrics from the tf.keras.optimizers, tf.keras.losses, and tf.keras.metrics modules, or you can define your own custom ones.
For example, suppose you want to compile your model with the Adam optimizer, the binary cross-entropy loss function, and the accuracy metric. You can do it as follows:
# Import the modules
import tensorflow as tf
from tensorflow.keras import optimizers, losses, metrics
# Compile the model
model.compile(
# Use the Adam optimizer with a learning rate of 0.001
optimizer=optimizers.Adam(learning_rate=0.001),
# Use the binary cross-entropy loss function
loss=losses.BinaryCrossentropy(),
# Use the accuracy metric
metrics=[metrics.BinaryAccuracy()]
)
This compilation could be suitable for a binary classification task, such as sentiment analysis, where the output is a single value between 0 and 1, indicating the positive or negative sentiment of the text.
To fit your model, you need to use the fit method of the tf.keras.models.Sequential class, and pass the input and output data, the batch size, the number of epochs, and the validation set as arguments. You can also use the tf.keras.callbacks module to add callbacks that can monitor and save your model’s performance during training.
For example, suppose you want to fit your model with a batch size of 32, 10 epochs, and 20% of the data as the validation set. You can also use the tf.keras.callbacks.ModelCheckpoint callback to save the best model based on the validation loss. You can do it as follows:
# Import the modules
import tensorflow as tf
from tensorflow.keras import callbacks
# Fit the model
model.fit(
# Use the input and output data
x=input_data,
y=output_data,
# Use a batch size of 32
batch_size=32,
# Use 10 epochs
epochs=10,
# Use 20% of the data as the validation set
validation_split=0.2,
# Use the ModelCheckpoint callback to save the best model
callbacks=[callbacks.ModelCheckpoint('best_model.h5', save_best_only=True, monitor='val_loss')]
)
This fitting could be suitable for any text processing task, as long as the input and output data are compatible with the model architecture.
As you can see, by using Keras and TensorFlow, you can easily compile and fit your model to the data, and customize it according to your needs and preferences.
In the next section, you will learn how to evaluate and save your model, and how to use it to make predictions on new data.
3.4. Evaluating and Saving the Model
After you have trained your RNN model, you need to evaluate its performance and save it for future use. In this section, you will learn how to use the tf.keras.models module to do both tasks.
To evaluate your model, you can use the model.evaluate() method, which takes the test data and the test labels as inputs, and returns the loss and the accuracy of the model on the test data. The loss is a measure of how well the model fits the data, and the accuracy is a measure of how many predictions the model got right. You can print these values to see how well your model performed.
For example, suppose you have a test data set called x_test and a test label set called y_test. You can evaluate your model as follows:
# Evaluate the model on the test data
loss, accuracy = model.evaluate(x_test, y_test)
# Print the loss and the accuracy
print("Loss:", loss)
print("Accuracy:", accuracy)
You can also use the model.predict() method to generate predictions for new data. This method takes a new data set as input, and returns a vector of probabilities for each possible output. You can use the np.argmax() function to get the index of the highest probability, which corresponds to the predicted label. You can compare the predicted label with the actual label to see if the model made a correct prediction.
For example, suppose you have a new data set called x_new and a new label set called y_new. You can generate predictions for the new data as follows:
# Import numpy
import numpy as np
# Generate predictions for the new data
predictions = model.predict(x_new)
# Get the index of the highest probability
predicted_labels = np.argmax(predictions, axis=1)
# Compare the predicted labels with the actual labels
for i in range(len(x_new)):
print("Input:", x_new[i])
print("Predicted label:", predicted_labels[i])
print("Actual label:", y_new[i])
To save your model, you can use the model.save() method, which takes a file name as input, and saves the model as a HDF5 file. This file contains the model architecture, the weights, the optimizer state, and the training configuration. You can load the model later using the tf.keras.models.load_model() function, which takes the file name as input, and returns the model object.
For example, suppose you want to save your model as “my_model.h5”. You can save your model as follows:
# Save the model as a HDF5 file
model.save("my_model.h5")
# Load the model later
model = tf.keras.models.load_model("my_model.h5")
Congratulations! You have learned how to use Keras and TensorFlow to build and train RNNs. In the next section, you will learn how to apply RNNs to text processing tasks, such as sentiment analysis, text generation, and machine translation.
4. How to Apply RNNs to Text Processing Tasks
In this section, you will learn how to apply your RNNs to text processing tasks using Keras and TensorFlow. You will learn how to use your trained model to perform tasks such as sentiment analysis, text generation, and machine translation. You will also learn how to use some of the built-in modules and functions from Keras and TensorFlow to simplify and enhance your tasks.
But first, what are text processing tasks? And why are they useful for your RNNs?
Text processing tasks are tasks that involve processing natural language text and performing some specific actions or outputs based on the text. For example, sentiment analysis is a text processing task that involves analyzing the emotion or attitude of the text, such as positive, negative, or neutral. Text generation is a text processing task that involves creating new text based on some input or context, such as a prompt or a topic. Machine translation is a text processing task that involves translating text from one language to another, such as from English to French.
Text processing tasks are useful for your RNNs because they allow you to apply your model to real-world problems and scenarios, and to demonstrate your model’s capabilities and performance. By using your RNNs for text processing tasks, you can create useful and interesting applications, such as chatbots, summarizers, recommender systems, and more.
So, how can you apply your RNNs to text processing tasks using Keras and TensorFlow? Let’s see some examples.
To apply your RNNs to sentiment analysis, you need to use the predict method of your trained model, and pass the text data as an argument. The predict method will return the output for the text data, which is a value between 0 and 1, indicating the positive or negative sentiment of the text. You can also use the tf.keras.preprocessing.text module to tokenize and pad the text data before passing it to the model.
For example, suppose you have a text data set with 100 samples, and you want to apply your model to perform sentiment analysis on it. You can do it as follows:
# Import the modules
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# Define the maximum number of words in the vocabulary
max_words = 10000
# Define the maximum length of the sequences
max_len = 100
# Create a tokenizer instance
tokenizer = Tokenizer(num_words=max_words)
# Fit the tokenizer on the text data
tokenizer.fit_on_texts(text_data)
# Convert the text data to sequences of integers
sequences = tokenizer.texts_to_sequences(text_data)
# Pad the sequences to the same length
padded_sequences = pad_sequences(sequences, maxlen=max_len)
# Predict the output for the text data
predictions = model.predict(x=padded_sequences, batch_size=32)
# Print the shape of the predictions
print('Predictions shape:', predictions.shape)
This application could be suitable for any text data set, as long as the text data and the model output are compatible.
To apply your RNNs to text generation, you need to use the predict method of your trained model, and pass the input text as an argument. The predict method will return the output for the input text, which is a sequence of probabilities for the next word in the vocabulary. You can also use the tf.random.categorical function to sample a word from the output probabilities, and append it to the input text. You can repeat this process until you reach a desired length or a stop token.
For example, suppose you have a vocabulary of 10000 words, and you want to apply your model to generate text based on a given prompt. You can do it as follows:
# Import the modules
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# Define the maximum number of words in the vocabulary
max_words = 10000
# Define the maximum length of the sequences
max_len = 100
# Create a tokenizer instance
tokenizer = Tokenizer(num_words=max_words)
# Fit the tokenizer on the text data
tokenizer.fit_on_texts(text_data)
# Define the prompt
prompt = 'Once upon a time'
# Convert the prompt to a sequence of integers
sequence = tokenizer.texts_to_sequences([prompt])[0]
# Pad the sequence to the same length
padded_sequence = pad_sequences([sequence], maxlen=max_len)
# Define the number of words to generate
num_words = 50
# Define the stop token
stop_token = '.'
# Initialize an empty list to store the generated words
generated_words = []
# Loop until the number of words or the stop token is reached
for i in range(num_words):
# Predict the output for the input text
output = model.predict(x=padded_sequence, batch_size=1)
# Sample a word from the output probabilities
word_index = tf.random.categorical(output, num_samples=1)[-1,0].numpy()
# Convert the word index to a word
word = tokenizer.index_word[word_index]
# Append the word to the generated words list
generated_words.append(word)
# Break the loop if the stop token is reached
if word == stop_token:
break
# Update the input text with the generated word
padded_sequence = tf.expand_dims(tf.concat([padded_sequence[:,1:], [[word_index]]], axis=-1), 0)
# Join the generated words with spaces
generated_text = ' '.join(generated_words)
# Print the generated text
print('Generated text:', prompt + ' ' + generated_text)
This application could be suitable for any text data set, as long as the input text and the model output are compatible.
To apply your RNNs to machine translation, you need to use the predict method of your trained model, and pass the source text as an argument. The predict method will return the output for the source text, which is a sequence of probabilities for the target text. You can also use the tf.argmax function to select the word with the highest probability, and append it to the target text. You can repeat this process until you reach a desired length or a stop token. You can also use the tf.keras.layers.Embedding layer to embed the source and target texts into a vector space.
For example, suppose you have a vocabulary of 10000 words for both the source and target languages, and you want to apply your model to translate text from English to French. You can do it as follows:
# Import the modules
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding
# Define the maximum number of words in the vocabulary
max_words = 10000
# Define the maximum length of the sequences
max_len = 100
# Define the embedding dimension
embedding_dim = 64
# Create a tokenizer instance for the source language
source_tokenizer = Tokenizer(num_words=max_words)
# Fit the tokenizer on the source text data
source_tokenizer.fit_on_texts(source_text_data)
# Create a tokenizer instance for the target language
target_tokenizer = Tokenizer(num_words=max_words)
# Fit the tokenizer on the target text data
target_tokenizer.fit_on_texts(target_text_data)
# Define the source text
source_text = 'How are you?'
# Convert the source text to a sequence of integers
source_sequence = source_tokenizer.texts_to_sequences([source_text])[0]
# Pad the source sequence to the same length
source_padded_sequence = pad_sequences([source_sequence], maxlen=max_len)
# Define the stop token
stop_token = '.'
# Initialize an empty list to store the translated words
translated_words = []
# Loop until the stop token is reached
while True:
# Predict the output for the source text
output = model.predict(x=source_padded_sequence, batch_size=1)
# Select the word with the highest probability
word_index = tf.argmax(output, axis=-1)[0,0].numpy()
# Convert the word index to a word
word = target_tokenizer.index_word[word_index]
# Append the word to the translated words list
translated_words.append(word)
# Break the loop if the stop token is reached
if word == stop_token:
break
# Update the source text with the translated word
source_padded_sequence = tf.expand_dims(tf.concat([source_padded_sequence[:,1:], [[word_index]]], axis=-1), 0)
# Join the translated words with spaces
translated_text = ' '.join(translated_words)
# Print the translated text
print('Translated text:', translated_text)
This application could be suitable for any pair of languages, as long as the source and target texts and the model output are compatible.
As you can see, by using Keras and TensorFlow, you can easily apply your RNNs to text processing tasks, and customize them according
4.1. Sentiment Analysis
In this section, you will learn how to use RNNs to perform sentiment analysis, which is the task of identifying and extracting the emotional tone or attitude of a text. Sentiment analysis can be useful for various applications, such as analyzing customer reviews, social media posts, or movie ratings.
But first, what is sentiment? And how can we measure it?
Sentiment is the subjective feeling or opinion that a text expresses or implies. Sentiment can be positive, negative, or neutral, depending on the mood, tone, or attitude of the text. Sentiment can also have different levels of intensity, such as very positive, slightly positive, or moderately negative.
To measure sentiment, we need to assign a numerical value or a label to each text, based on some criteria or rules. For example, we can use a scale from -1 to 1, where -1 means very negative, 0 means neutral, and 1 means very positive. Alternatively, we can use a categorical label, such as positive, negative, or neutral. The process of assigning a sentiment value or label to a text is called sentiment classification.
However, sentiment classification is not an easy task, as different texts can have different meanings, contexts, and nuances. For example, the same word or phrase can have different sentiments depending on the situation, such as “I love this movie” versus “I love this movie, not”. Moreover, some texts can have mixed or contradictory sentiments, such as “The movie was good, but the ending was terrible”. Therefore, we need a model that can capture the complexity and variability of natural language.
This is where RNNs come in handy. RNNs can process sequential data, such as text, and capture the temporal dependencies and the context of the sequence. By using RNNs, we can encode the meaning and the sentiment of each word in the text, and combine them to produce a sentiment score or label for the whole text.
So, how can we use RNNs to perform sentiment analysis? In the next subsections, you will learn the steps to build and train a sentiment classifier using Keras and TensorFlow.
4.2. Text Generation
In this section, you will learn how to use RNNs to perform text generation, which is the task of creating new text based on some input or context. Text generation can be useful for various applications, such as writing stories, poems, lyrics, captions, headlines, or summaries.
But first, what is text generation? And how can we do it?
Text generation is the process of producing new text that is coherent, meaningful, and relevant to the input or context. Text generation can be done in different ways, such as using rules, templates, or statistical models. However, one of the most popular and powerful methods is to use neural networks, especially RNNs.
RNNs can generate text by learning from a large corpus of text data, such as books, articles, or tweets. By using RNNs, we can model the probability distribution of the next word or character given the previous words or characters in the sequence. By sampling from this distribution, we can generate new text that follows the style and the structure of the original data.
For example, suppose we want to generate a new sentence based on the previous sentence, such as “The sky is blue”. An RNN can learn from the data that the next word is likely to be an adjective, a noun, or a punctuation, and assign a probability to each possible word. Then, we can sample a word from this distribution, such as “and”, and append it to the generated sentence. We can repeat this process until we reach the end of the sentence, such as “The sky is blue and clear”.
However, not all RNNs are the same. There are different types of RNNs that have different architectures and functionalities. In the previous section, you learned about three common types of RNN cells: the basic RNN cell, the long short-term memory (LSTM) cell, and the gated recurrent unit (GRU) cell. In this section, you will learn how to use these cells to build and train a text generator using Keras and TensorFlow.
4.3. Machine Translation
In this section, you will learn how to use RNNs to perform machine translation, which is the task of translating a text from one language to another. Machine translation can be useful for various applications, such as communicating with people from different countries, accessing information from foreign sources, or learning new languages.
But first, what is machine translation? And how can we do it?
Machine translation is the process of converting a text from a source language to a target language, while preserving the meaning and the style of the original text. Machine translation can be done in different ways, such as using rules, dictionaries, or statistical models. However, one of the most popular and powerful methods is to use neural networks, especially RNNs.
RNNs can perform machine translation by learning from a large corpus of parallel texts, such as sentences or documents that are translated from one language to another. By using RNNs, we can encode the meaning and the structure of the source text into a vector of numbers, and decode this vector into the target text using another RNN. This way, we can generate a translation that is fluent, accurate, and relevant to the context.
For example, suppose we want to translate a sentence from English to French, such as “Hello, how are you?”. An RNN can learn from the data that the corresponding sentence in French is “Bonjour, comment allez-vous?”. Then, it can use an encoder RNN to convert the English sentence into a vector, and use a decoder RNN to convert the vector into the French sentence.
However, not all RNNs are the same. There are different types of RNNs that have different architectures and functionalities. In the previous sections, you learned about three common types of RNN cells: the basic RNN cell, the long short-term memory (LSTM) cell, and the gated recurrent unit (GRU) cell. In this section, you will learn how to use these cells to build and train a machine translation model using Keras and TensorFlow.
5. Conclusion
In this blog, you have learned how to use Keras and TensorFlow to work with text and recurrent neural networks (RNNs). You have learned the theory and practice of RNNs and how to apply them to sentiment analysis, text generation, and machine translation tasks.
You have learned how to:
- Understand what RNNs are and why they are useful for working with text.
- Use different types of RNN cells, such as the basic RNN cell, the long short-term memory (LSTM) cell, and the gated recurrent unit (GRU) cell.
- Build and train RNN models using Keras and TensorFlow.
- Evaluate and save your RNN models.
- Perform sentiment analysis using RNNs.
- Generate text using RNNs.
- Translate text using RNNs.
By following this blog, you have gained valuable skills and knowledge that can help you create amazing applications with text and RNNs. You have also seen how easy and powerful it is to use Keras and TensorFlow to work with text and RNNs.
We hope you enjoyed this blog and learned something new and useful. If you have any questions, feedback, or suggestions, please feel free to leave a comment below. Thank you for reading and happy coding!



