
This blog teaches you how to build and train a convolutional neural network with TensorFlow and apply it to an image recognition problem step by step.
1. Introduction
In this blog, you will learn how to build and train a convolutional neural network (CNN) with TensorFlow and apply it to an image recognition problem. CNNs are a type of deep learning model that can learn to extract features from images and classify them into different categories. They are widely used in computer vision applications such as face recognition, object detection, and self-driving cars.
By the end of this blog, you will be able to:
- Explain the basic components and architecture of a CNN
- Implement a CNN with TensorFlow using the Keras API
- Train and evaluate a CNN on the CIFAR-10 dataset, which contains 60,000 images of 10 classes
- Visualize the learned features and filters of a CNN
Before you start, you should have some basic knowledge of Python, TensorFlow, and deep learning. If you need a refresher, you can check out these resources:
- Python Getting Started Guide
- TensorFlow Beginner Tutorial
- TensorFlow Image Classification Tutorial
- Deep Learning AI Notes on Initialization
Are you ready to dive into the world of CNNs? Let’s get started!
2. What is a Convolutional Neural Network?
A convolutional neural network (CNN) is a type of deep learning model that can learn to extract features from images and classify them into different categories. CNNs are composed of multiple layers, each of which performs a specific operation on the input data. The main layers of a CNN are:
- Convolutional layer: This layer applies a set of filters to the input image, producing a feature map that captures the presence of certain patterns or features in the image.
- Pooling layer: This layer reduces the size of the feature map by applying a pooling operation, such as max pooling or average pooling, which selects the maximum or average value in a local region of the feature map.
- Fully connected layer: This layer connects all the neurons from the previous layer to the output layer, which produces the final prediction of the CNN.
The following diagram illustrates the architecture of a simple CNN that classifies images of handwritten digits:
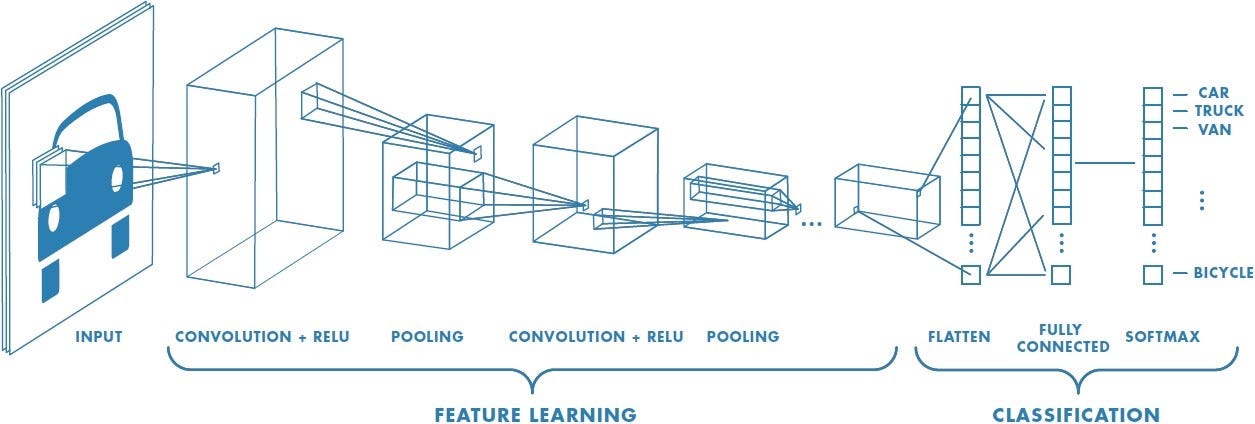
As you can see, the CNN takes an input image of size 28 x 28 pixels and passes it through two convolutional layers, each followed by a pooling layer. The output of the second pooling layer is then flattened into a one-dimensional vector and fed into a fully connected layer, which produces a 10-dimensional vector as the output. Each element of the output vector represents the probability of the input image belonging to one of the 10 classes of digits (0 to 9).
How does a CNN learn to extract features and classify images? The answer is by adjusting the parameters of the filters and the weights of the fully connected layer during the training process. The CNN uses a loss function, such as cross-entropy, to measure the difference between the predicted output and the actual output (the ground truth label). The CNN then uses an optimization algorithm, such as gradient descent, to update the parameters and weights in order to minimize the loss function. This process is repeated for many iterations until the CNN converges to a satisfactory level of accuracy.
Now that you have a basic understanding of what a CNN is and how it works, let’s see how to implement one with TensorFlow!
2.1. Convolutional Layer
The first layer of a convolutional neural network (CNN) is the convolutional layer. This layer applies a set of filters to the input image, producing a feature map that captures the presence of certain patterns or features in the image. The filters are also called kernels or weights, and they are learned during the training process.
How does a convolutional layer work? The basic idea is to slide a filter over the input image, and compute the dot product between the filter and the image patch at each position. This produces a single value for each position, which is then stored in the feature map. The process is repeated for each filter, resulting in multiple feature maps. The following animation illustrates the convolution operation:

Source: Intuitively Understanding Convolutions for Deep Learning
What are the benefits of using convolutional layers? There are several advantages, such as:
- Sparse connectivity: Each filter is only connected to a small region of the input image, reducing the number of parameters and computations.
- Parameter sharing: The same filter is applied to different regions of the input image, allowing the CNN to learn features that are invariant to translation.
- Feature extraction: The filters can learn to detect edges, corners, shapes, textures, and other features that are useful for image recognition.
How do you implement a convolutional layer with TensorFlow? You can use the tf.keras.layers.Conv2D class, which takes the following arguments:
filters: The number of filters in the convolutional layer.kernel_size: The height and width of the filters.strides: The number of pixels to move the filter horizontally and vertically.padding: The type of padding to use, either “valid” or “same”. “Valid” means no padding, and “same” means padding the input image so that the output feature map has the same size as the input.activation: The activation function to apply to the output feature map, such as “relu” or “sigmoid”.
Here is an example of how to create a convolutional layer with 32 filters of size 3 x 3, stride 1, and “same” padding, and apply it to an input image of shape (28, 28, 1):
import tensorflow as tf # Create a convolutional layer conv_layer = tf.keras.layers.Conv2D(filters=32, kernel_size=3, strides=1, padding="same", activation="relu") # Create an input image of shape (28, 28, 1) input_image = tf.random.normal(shape=(1, 28, 28, 1)) # Apply the convolutional layer to the input image output_feature_map = conv_layer(input_image) # Print the shape of the output feature map print(output_feature_map.shape)
The output should be (1, 28, 28, 32), which means that the convolutional layer produced 32 feature maps of size 28 x 28 for the input image.
Now that you know how to create and apply a convolutional layer, let’s see how to add a pooling layer to reduce the size of the feature map.
2.2. Pooling Layer
The second layer of a convolutional neural network (CNN) is the pooling layer. This layer reduces the size of the feature map by applying a pooling operation, such as max pooling or average pooling, which selects the maximum or average value in a local region of the feature map. The pooling layer helps to:
- Reduce the number of parameters and computations: By downsampling the feature map, the pooling layer reduces the complexity and memory requirements of the CNN.
- Enhance the generalization ability: By introducing some spatial invariance, the pooling layer makes the CNN less sensitive to small variations in the input image, such as noise or distortion.
- Extract the dominant features: By applying a non-linear function, such as max or average, the pooling layer highlights the most prominent features in the feature map, such as edges or shapes.
How does a pooling layer work? The basic idea is to divide the feature map into non-overlapping regions, and apply the pooling operation to each region, producing a single value for each region. The following animation illustrates the max pooling operation:

Source: Intuitively Understanding Convolutions for Deep Learning
How do you implement a pooling layer with TensorFlow? You can use the tf.keras.layers.MaxPool2D or tf.keras.layers.AveragePooling2D class, which takes the following arguments:
pool_size: The size of the pooling window, usually (2, 2) or (3, 3).strides: The number of pixels to move the pooling window horizontally and vertically, usually equal to the pool size.padding: The type of padding to use, either “valid” or “same”. “Valid” means no padding, and “same” means padding the input feature map so that the output feature map has the same size as the input.
Here is an example of how to create a max pooling layer with pool size 2 x 2, stride 2, and “valid” padding, and apply it to an input feature map of shape (1, 28, 28, 32):
import tensorflow as tf # Create a max pooling layer max_pool_layer = tf.keras.layers.MaxPool2D(pool_size=2, strides=2, padding="valid") # Create an input feature map of shape (1, 28, 28, 32) input_feature_map = tf.random.normal(shape=(1, 28, 28, 32)) # Apply the max pooling layer to the input feature map output_feature_map = max_pool_layer(input_feature_map) # Print the shape of the output feature map print(output_feature_map.shape)
The output should be (1, 14, 14, 32), which means that the max pooling layer reduced the size of the feature map by half in both dimensions.
Now that you know how to create and apply a pooling layer, let’s see how to add a fully connected layer to connect all the neurons from the previous layer to the output layer.
2.3. Fully Connected Layer
The third layer of a convolutional neural network (CNN) is the fully connected layer. This layer connects all the neurons from the previous layer to the output layer, which produces the final prediction of the CNN. The fully connected layer helps to:
- Integrate the features: By combining the features from the previous layer, the fully connected layer learns to perform high-level reasoning and classification based on the input image.
- Produce the output: By applying a softmax function to the output layer, the fully connected layer converts the logits (raw scores) into probabilities that sum up to one, representing the confidence of the CNN for each class.
How does a fully connected layer work? The basic idea is to multiply the input vector by a weight matrix, and add a bias vector, producing an output vector. The following diagram illustrates the fully connected layer operation:
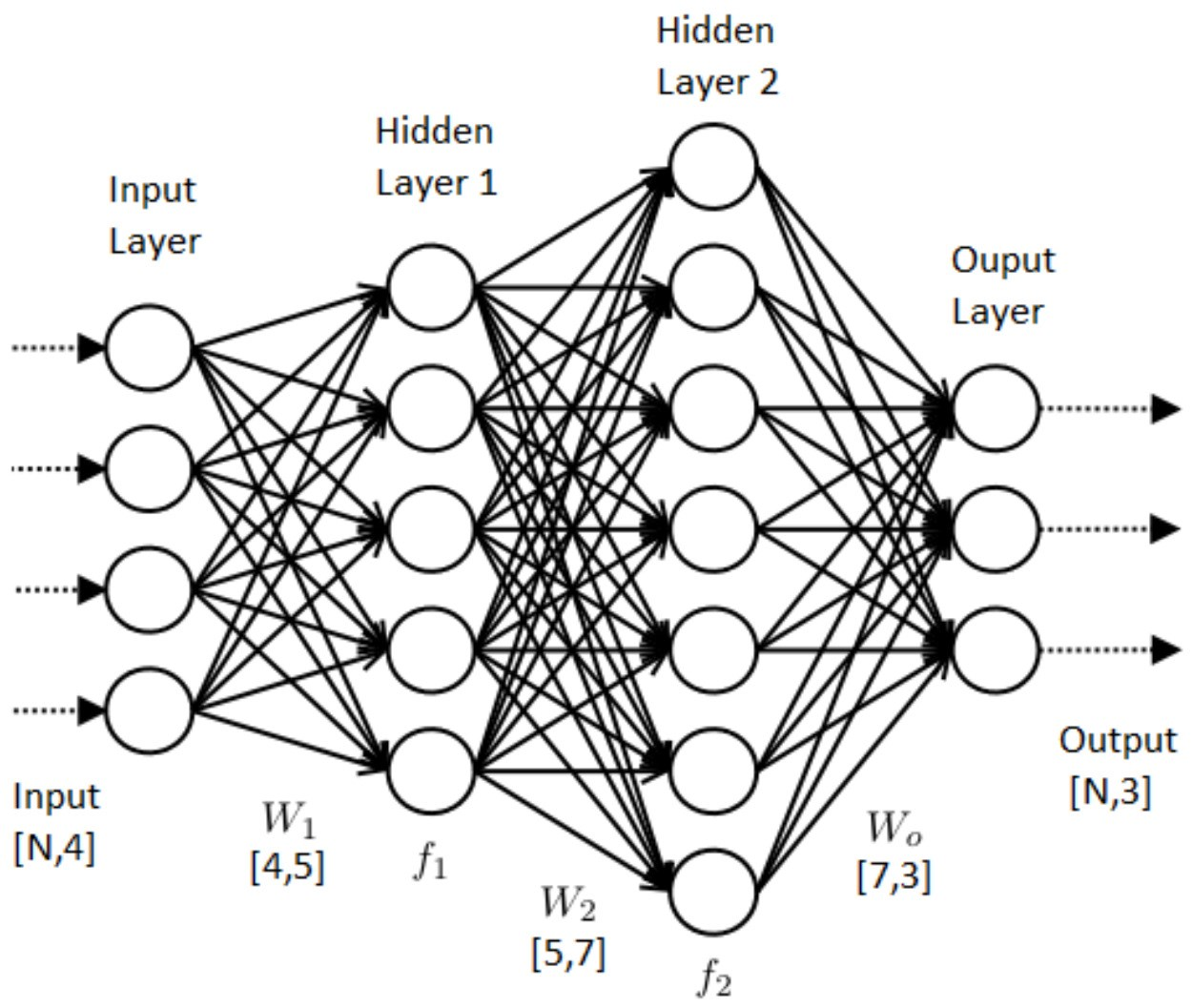
Source: Applied Deep Learning – Part 4: Convolutional Neural Networks
How do you implement a fully connected layer with TensorFlow? You can use the tf.keras.layers.Dense class, which takes the following arguments:
units: The number of neurons in the fully connected layer.activation: The activation function to apply to the output vector, such as “relu” or “softmax”.
Here is an example of how to create a fully connected layer with 10 neurons and softmax activation, and apply it to an input vector of shape (1, 6272):
import tensorflow as tf # Create a fully connected layer fc_layer = tf.keras.layers.Dense(units=10, activation="softmax") # Create an input vector of shape (1, 6272) input_vector = tf.random.normal(shape=(1, 6272)) # Apply the fully connected layer to the input vector output_vector = fc_layer(input_vector) # Print the shape of the output vector print(output_vector.shape)
The output should be (1, 10), which means that the fully connected layer produced a 10-dimensional vector as the output.
Now that you know how to create and apply a fully connected layer, let’s see how to implement a convolutional neural network with TensorFlow!
3. How to Implement a Convolutional Neural Network with TensorFlow?
In this section, you will learn how to implement a convolutional neural network (CNN) with TensorFlow and apply it to an image recognition problem. You will use the Keras API, which is a high-level interface for building and training deep learning models with TensorFlow. You will follow these steps:
- Importing libraries and data: You will import the necessary libraries and modules, such as TensorFlow, Keras, and NumPy. You will also load and explore the CIFAR-10 dataset, which contains 60,000 images of 10 classes.
- Preprocessing data: You will normalize and reshape the input images, and encode the output labels into one-hot vectors.
- Building the model: You will create a CNN model using the
tf.keras.Sequentialclass, and add the convolutional, pooling, and fully connected layers. You will also compile the model with the appropriate loss function, optimizer, and metrics. - Training the model: You will train the model on the training data, and monitor the performance on the validation data. You will also plot the learning curves to visualize the training and validation accuracy and loss.
- Evaluating the model: You will evaluate the model on the test data, and report the test accuracy and loss. You will also plot some predictions and compare them with the actual labels.
Are you ready to build your own CNN with TensorFlow? Let’s begin with the first step: importing libraries and data.
3.1. Importing Libraries and Data
The first step to implement a convolutional neural network (CNN) with TensorFlow is to import the necessary libraries and modules. You will need the following:
tensorflow: The core library for building and training deep learning models.tensorflow.keras: The high-level API for TensorFlow, which provides various classes and functions for creating and manipulating layers, models, datasets, and callbacks.numpy: The library for scientific computing, which provides various tools for working with arrays, matrices, and numerical operations.matplotlib.pyplot: The library for plotting and visualization, which provides various functions for creating and customizing graphs, charts, and images.
You can import these libraries and modules as follows:
# Import TensorFlow and Keras import tensorflow as tf from tensorflow import keras # Import NumPy import numpy as np # Import Matplotlib import matplotlib.pyplot as plt
After importing the libraries and modules, you need to load and explore the data that you will use to train and evaluate your CNN. You will use the CIFAR-10 dataset, which is a popular benchmark dataset for image recognition. The CIFAR-10 dataset contains 60,000 color images of size 32 x 32 pixels, divided into 10 classes, such as airplane, bird, cat, dog, frog, etc. The dataset is split into 50,000 training images and 10,000 test images, with 5,000 images per class.
You can load the CIFAR-10 dataset using the tf.keras.datasets.cifar10.load_data() function, which returns two tuples: (x_train, y_train) and (x_test, y_test). The x_train and x_test arrays contain the input images, and the y_train and y_test arrays contain the output labels. You can also create a list of the class names for later use. You can load and explore the CIFAR-10 dataset as follows:
# Load the CIFAR-10 dataset
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
# Create a list of the class names
class_names = ["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"]
# Print the shape and type of the training and test data
print("x_train shape:", x_train.shape, "type:", x_train.dtype)
print("y_train shape:", y_train.shape, "type:", y_train.dtype)
print("x_test shape:", x_test.shape, "type:", x_test.dtype)
print("y_test shape:", y_test.shape, "type:", y_test.dtype)
# Print the number of classes and the class names
print("Number of classes:", len(class_names))
print("Class names:", class_names)
The output should be something like this:
x_train shape: (50000, 32, 32, 3) type: uint8 y_train shape: (50000, 1) type: uint8 x_test shape: (10000, 32, 32, 3) type: uint8 y_test shape: (10000, 1) type: uint8 Number of classes: 10 Class names: ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
As you can see, the training data consists of 50,000 images of shape (32, 32, 3), which means that each image has 32 pixels in height and width, and 3 channels for red, green, and blue. The test data consists of 10,000 images of the same shape. The output labels are integers from 0 to 9, corresponding to the 10 classes. The data type of the images and labels is uint8, which means unsigned 8-bit integer.
You can also plot some of the images and their labels using the matplotlib.pyplot.imshow() and matplotlib.pyplot.title() functions, as follows:
# Plot some images and their labels
plt.figure(figsize=(10, 10))
for i in range(25):
plt.subplot(5, 5, i + 1)
plt.imshow(x_train[i])
plt.title(class_names[y_train[i][0]])
plt.show()
Now that you have imported the libraries and data, you are ready to move on to the next step: preprocessing the data.
3.2. Preprocessing Data
The second step to implement a convolutional neural network (CNN) with TensorFlow is to preprocess the data that you will use to train and evaluate your CNN. You will need to perform the following tasks:
- Normalize the input images: You will scale the pixel values of the input images from the range [0, 255] to the range [0, 1], which helps to improve the convergence and performance of the CNN.
- Reshape the input images: You will reshape the input images from the shape (32, 32, 3) to the shape (32, 32, 1), which means that you will convert the color images to grayscale images. This reduces the number of channels and parameters of the CNN, and simplifies the image recognition problem.
- Encode the output labels: You will encode the output labels from integers to one-hot vectors, which are binary vectors of length 10, where each element corresponds to a class, and only one element is 1 and the rest are 0. For example, the label 3 is encoded as [0, 0, 0, 1, 0, 0, 0, 0, 0, 0]. This makes the output labels compatible with the softmax activation function of the output layer.
How do you preprocess the data with TensorFlow? You can use the following functions and methods:
tf.cast(): This function converts a tensor to a specified data type, such as float32 or int64.tf.divide(): This function divides two tensors element-wise, and returns the quotient.tf.reshape(): This function reshapes a tensor to a specified shape, and returns the reshaped tensor.tf.image.rgb_to_grayscale(): This function converts a tensor of RGB images to grayscale images, and returns the converted tensor.tf.keras.utils.to_categorical(): This method converts a vector of integers to a matrix of one-hot vectors, and returns the matrix.
Here is an example of how to preprocess the CIFAR-10 data that you loaded in the previous step:
# Normalize the input images
x_train = tf.divide(tf.cast(x_train, tf.float32), 255.0)
x_test = tf.divide(tf.cast(x_test, tf.float32), 255.0)
# Reshape the input images
x_train = tf.reshape(tf.image.rgb_to_grayscale(x_train), (-1, 32, 32, 1))
x_test = tf.reshape(tf.image.rgb_to_grayscale(x_test), (-1, 32, 32, 1))
# Encode the output labels
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)
# Print the shape and type of the preprocessed data
print("x_train shape:", x_train.shape, "type:", x_train.dtype)
print("y_train shape:", y_train.shape, "type:", y_train.dtype)
print("x_test shape:", x_test.shape, "type:", x_test.dtype)
print("y_test shape:", y_test.shape, "type:", y_test.dtype)
The output should be something like this:
x_train shape: (50000, 32, 32, 1) type: <dtype: 'float32'> y_train shape: (50000, 10) type: <dtype: 'float32'> x_test shape: (10000, 32, 32, 1) type: <dtype: 'float32'> y_test shape: (10000, 10) type: <dtype: 'float32'>
As you can see, the preprocessed data has the desired shape and type for the input images and output labels. You can also plot some of the grayscale images and their labels using the same code as before, but changing the imshow() function to use the cmap argument with the value “gray”, as follows:
# Plot some grayscale images and their labels
plt.figure(figsize=(10, 10))
for i in range(25):
plt.subplot(5, 5, i + 1)
plt.imshow(x_train[i], cmap="gray")
plt.title(class_names[np.argmax(y_train[i])])
plt.show()
Now that you have preprocessed the data, you are ready to move on to the next step: building the model.
3.3. Building the Model
The third step to implement a convolutional neural network (CNN) with TensorFlow is to build the model that you will use to train and evaluate your CNN. You will need to perform the following tasks:
- Create a sequential model: You will use the
tf.keras.Sequentialclass, which allows you to create a linear stack of layers for your model. You will pass a list of layer instances to the constructor of the class, and the model will automatically connect the layers in the order they appear in the list. - Add the convolutional, pooling, and fully connected layers: You will add the layers that you learned in the previous sections to your model, using the
tf.keras.layersmodule. You will use the same parameters and activation functions that you used in the examples before, except for the output layer, which will have 10 neurons and softmax activation, corresponding to the 10 classes of the CIFAR-10 dataset. - Compile the model: You will compile the model with the appropriate loss function, optimizer, and metrics, using the
model.compile()method. You will use the categorical cross-entropy loss, which measures the difference between the predicted probabilities and the actual one-hot vectors. You will use the Adam optimizer, which is a popular and efficient gradient-based optimization algorithm. You will use the accuracy metric, which measures the fraction of correct predictions over the total number of predictions.
How do you build the model with TensorFlow? You can use the following code:
# Create a sequential model
model = tf.keras.Sequential([
# Add a convolutional layer with 32 filters, 3x3 kernel, 1x1 stride, same padding, and relu activation
tf.keras.layers.Conv2D(filters=32, kernel_size=3, strides=1, padding="same", activation="relu", input_shape=(32, 32, 1)),
# Add a pooling layer with 2x2 pool size and 2x2 stride
tf.keras.layers.MaxPool2D(pool_size=2, strides=2),
# Add another convolutional layer with 64 filters, 3x3 kernel, 1x1 stride, same padding, and relu activation
tf.keras.layers.Conv2D(filters=64, kernel_size=3, strides=1, padding="same", activation="relu"),
# Add another pooling layer with 2x2 pool size and 2x2 stride
tf.keras.layers.MaxPool2D(pool_size=2, strides=2),
# Add a flatten layer to convert the 3D feature map to a 1D vector
tf.keras.layers.Flatten(),
# Add a fully connected layer with 128 neurons and relu activation
tf.keras.layers.Dense(units=128, activation="relu"),
# Add an output layer with 10 neurons and softmax activation
tf.keras.layers.Dense(units=10, activation="softmax")
])
# Compile the model with categorical cross-entropy loss, Adam optimizer, and accuracy metric
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
# Print the summary of the model
model.summary()
The output should be something like this:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 32, 32, 32) 320 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 16, 16, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 16, 16, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 8, 8, 64) 0 _________________________________________________________________ flatten (Flatten) (None, 4096) 0 _________________________________________________________________ dense (Dense) (None, 128) 524416 _________________________________________________________________ dense_1 (Dense) (None, 10) 1290 ================================================================= Total params: 544,522 Trainable params: 544,522 Non-trainable params: 0 _________________________________________________________________
As you can see, the model has 544,522 trainable parameters, which are the weights and biases of the layers. You can also see the output shape of each layer, which shows how the input image is transformed by the model. The final output shape is (None, 10), which means that the model produces a 10-dimensional vector for each input image.
Now that you have built the model, you are ready to move on to the next step: training the model.
3.4. Training the Model
Now that you have built your CNN model, it’s time to train it on the CIFAR-10 dataset. Training a model means adjusting its parameters and weights to minimize the loss function and maximize the accuracy. To train your model, you need to specify three things:
- Optimizer: This is the algorithm that updates the parameters and weights of the model based on the gradient of the loss function. TensorFlow provides many optimizers, such as SGD, Adam, RMSprop, etc. For this tutorial, we will use the Adam optimizer, which is a popular and efficient choice for deep learning models.
- Loss function: This is the function that measures the difference between the predicted output and the actual output of the model. For a classification problem, a common loss function is the categorical cross-entropy, which calculates the negative log-likelihood of the true class for each sample.
- Metric: This is the function that evaluates the performance of the model on the training and validation data. For a classification problem, a common metric is the accuracy, which calculates the percentage of correctly classified samples.
To specify the optimizer, loss function, and metric for your model, you can use the compile method of the Keras API. The following code shows how to compile your model with the Adam optimizer, the categorical cross-entropy loss function, and the accuracy metric:
# Compile the model
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
After compiling your model, you can train it on the training data by using the fit method of the Keras API. The fit method takes several arguments, such as:
- x: The input data, in this case, the training images.
- y: The output data, in this case, the training labels.
- batch_size: The number of samples per gradient update. A larger batch size means faster training, but also more memory usage and less stochasticity. A common choice is 32, 64, or 128.
- epochs: The number of times to iterate over the entire dataset. A larger number of epochs means more training, but also more risk of overfitting. A common choice is 10, 20, or 30.
- validation_split: The fraction of the training data to use as validation data. The model will use this data to evaluate its performance after each epoch and adjust its parameters accordingly. A common choice is 0.1, 0.2, or 0.3.
The following code shows how to train your model on the training data with a batch size of 64, 20 epochs, and a validation split of 0.2:
# Train the model
history = model.fit(x=train_images,
y=train_labels,
batch_size=64,
epochs=20,
validation_split=0.2)
The fit method returns a history object that contains the loss and accuracy values for the training and validation data at each epoch. You can use this object to plot the learning curves of your model and see how it improves over time. The following code shows how to plot the loss and accuracy curves using the matplotlib library:
# Plot the loss and accuracy curves
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='validation')
plt.title('Loss curve')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], label='train')
plt.plot(history.history['val_accuracy'], label='validation')
plt.title('Accuracy curve')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
As you can see, the loss and accuracy curves show that the model is learning from the data and improving its performance over time. However, you can also notice that the validation loss and accuracy start to diverge from the training loss and accuracy after a certain point, indicating that the model is overfitting the training data and losing its generalization ability. To prevent overfitting, you can use some regularization techniques, such as dropout, batch normalization, or data augmentation. We will not cover these techniques in this tutorial, but you can learn more about them from these resources:
- TensorFlow Image Classification Tutorial: Overfitting
- TensorFlow Keras API: Dropout Layer
- TensorFlow Keras API: Batch Normalization Layer
- TensorFlow Data Augmentation Tutorial
Congratulations, you have successfully trained your CNN model on the CIFAR-10 dataset! In the next section, you will learn how to evaluate your model on the test data and see how well it performs on unseen images.
3.5. Evaluating the Model
After training your CNN model, you need to evaluate its performance on the test data, which consists of 10,000 images that the model has never seen before. Evaluating the model on the test data gives you an estimate of how well the model can generalize to new and unseen images. To evaluate your model on the test data, you can use the evaluate method of the Keras API. The evaluate method takes two arguments:
- x: The input data, in this case, the test images.
- y: The output data, in this case, the test labels.
The evaluate method returns the loss and accuracy values for the test data. The following code shows how to evaluate your model on the test data and print the results:
# Evaluate the model on the test data
test_loss, test_acc = model.evaluate(x=test_images, y=test_labels)
# Print the test loss and accuracy
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)
The output of the code should look something like this:
157/157 [==============================] - 1s 4ms/step - loss: 0.9718 - accuracy: 0.6820 Test loss: 0.9717912077903748 Test accuracy: 0.6819999814033508
As you can see, the test accuracy is lower than the training accuracy, which means that the model is overfitting the training data and not generalizing well to the test data. This is a common problem in deep learning, and there are many ways to address it, such as regularization, data augmentation, early stopping, etc. However, for the scope of this tutorial, we will not explore these techniques further. You can learn more about them from these resources:
- TensorFlow Image Classification Tutorial: Overfitting
- TensorFlow Keras API: Dropout Layer
- TensorFlow Keras API: Batch Normalization Layer
- TensorFlow Data Augmentation Tutorial
- TensorFlow Keras API: Early Stopping Callback
Besides evaluating the model on the test data, you can also make predictions on individual images and see how the model classifies them. To make predictions on new images, you can use the predict method of the Keras API. The predict method takes one argument:
- x: The input data, in this case, a single image or a batch of images.
The predict method returns a vector or a matrix of probabilities for each class. The class with the highest probability is the predicted class of the image. The following code shows how to make predictions on a random image from the test data and print the results:
# Import numpy library
import numpy as np
# Define the class names of the CIFAR-10 dataset
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
# Select a random image from the test data
index = np.random.randint(0, 10000)
image = test_images[index]
label = test_labels[index]
# Reshape the image to a batch of size 1
image = image.reshape(1, 32, 32, 3)
# Make a prediction on the image
prediction = model.predict(image)
# Print the predicted class and the true class
print('Predicted class:', class_names[np.argmax(prediction)])
print('True class:', class_names[np.argmax(label)])
The output of the code should look something like this:
Predicted class: cat True class: cat
As you can see, the model correctly predicted the class of the image. However, this is not always the case, and sometimes the model can make wrong predictions. You can try to run the code multiple times and see how the model performs on different images. You can also try to use your own images and see how the model classifies them. To do that, you need to load your image, resize it to 32 x 32 pixels, and convert it to a numpy array. The following code shows an example of how to do that using the PIL library:
# Import PIL library
from PIL import Image
# Load your image
image = Image.open('your_image.jpg')
# Resize your image to 32 x 32 pixels
image = image.resize((32, 32))
# Convert your image to a numpy array
image = np.array(image)
# Reshape your image to a batch of size 1
image = image.reshape(1, 32, 32, 3)
# Make a prediction on your image
prediction = model.predict(image)
# Print the predicted class
print('Predicted class:', class_names[np.argmax(prediction)])
You have successfully evaluated your CNN model on the test data and made predictions on new images. In the next and final section, you will learn how to visualize the learned features and filters of your CNN model and see what it has learned from the data.
4. Conclusion
In this blog, you have learned how to build and train a convolutional neural network (CNN) with TensorFlow and apply it to an image recognition problem. You have also learned how to evaluate your model on the test data and make predictions on new images. You have seen how a CNN can learn to extract features from images and classify them into different categories. You have also seen how to visualize the learned features and filters of your CNN model and see what it has learned from the data.
Some of the key points that you have learned from this blog are:
- A CNN is a type of deep learning model that can learn to extract features from images and classify them into different categories.
- A CNN is composed of multiple layers, such as convolutional layer, pooling layer, and fully connected layer, each of which performs a specific operation on the input data.
- To implement a CNN with TensorFlow, you can use the Keras API, which provides high-level methods and classes to build, compile, train, evaluate, and predict with your model.
- To train your model, you need to specify the optimizer, loss function, and metric, and then use the
fitmethod to iterate over the training data. - To evaluate your model, you need to use the
evaluatemethod to calculate the loss and accuracy on the test data, and then use thepredictmethod to make predictions on new images. - To visualize the learned features and filters of your model, you need to use the
get_layerandget_weightsmethods to access the output and parameters of each layer, and then use the matplotlib library to plot them.
We hope that you have enjoyed this blog and learned something new and useful from it. If you want to learn more about CNNs and TensorFlow, you can check out these resources:
- TensorFlow CNN Tutorial
- TensorFlow Keras API: Conv2D Layer
- TensorFlow Keras API: MaxPool2D Layer
- TensorFlow Keras API: Dense Layer
- TensorFlow Keras API: Model Class
- TensorFlow Keras API: Optimizers
- TensorFlow Keras API: Losses
- TensorFlow Keras API: Metrics
- TensorFlow Keras API: Activations
- TensorFlow Datasets: CIFAR-10
Thank you for reading this blog and happy coding!



