
This blog teaches you how to build and train a neural network with TensorFlow and apply it to a multiclass classification problem using softmax layer.
1. Introduction
Deep learning is a branch of machine learning that uses artificial neural networks to learn from data and perform tasks such as classification, regression, generation, and more. In this blog series, you will learn how to build and train your own neural networks from scratch using Python and TensorFlow, one of the most popular frameworks for deep learning.
In this first blog, you will learn the basics of neural networks and how they work. You will also learn how to use TensorFlow to create and manipulate tensors, which are the building blocks of neural networks. Finally, you will apply your knowledge to a multiclass classification problem, where you will use a neural network to classify images of handwritten digits.
By the end of this blog, you will be able to:
- Explain what a neural network is and how it learns from data
- Use TensorFlow to perform tensor operations and create computational graphs
- Build and train a neural network with TensorFlow and apply it to a classification problem
Are you ready to dive into the world of deep learning? Let’s get started!
2. What is a Neural Network?
A neural network is a computational model that mimics the structure and function of biological neurons. A neural network consists of many interconnected units, called neurons, that process and transmit information. A neural network can learn from data and perform tasks such as classification, regression, generation, and more.
But how does a neural network learn from data? And how does it perform tasks? To answer these questions, you need to understand the basic components and operations of a neural network. In this section, you will learn about:
- Neurons and layers
- Activation functions
- Network architecture
Let’s start with the most fundamental unit of a neural network: the neuron.
2.1. Neurons and Layers
A neuron is a basic unit of a neural network that takes some inputs, performs some computation, and produces an output. A neuron can be represented as a function that maps a vector of inputs $\mathbf{x} = (x_1, x_2, …, x_n)$ to a scalar output $y$.
One of the simplest types of neurons is the linear neuron, which computes a weighted sum of the inputs and adds a bias term. The output of a linear neuron can be written as:
$$y = w_1 x_1 + w_2 x_2 + … + w_n x_n + b$$
where $\mathbf{w} = (w_1, w_2, …, w_n)$ are the weights and $b$ is the bias. The weights and bias are parameters that can be learned from data to adjust the output of the neuron. You can think of the weights as the strength of the connection between the inputs and the output, and the bias as the offset of the output.
A linear neuron can also be written in a more compact form using the dot product notation:
$$y = \mathbf{w} \cdot \mathbf{x} + b$$
Here is a graphical representation of a linear neuron:

A single neuron can only perform a simple linear transformation of the inputs, which limits its expressive power. To create more complex and nonlinear functions, we can combine multiple neurons into layers and stack multiple layers into a network. A layer is a group of neurons that share the same inputs and produce a vector of outputs. A network is a sequence of layers that take an input vector and produce an output vector.
Here is an example of a network with two layers:
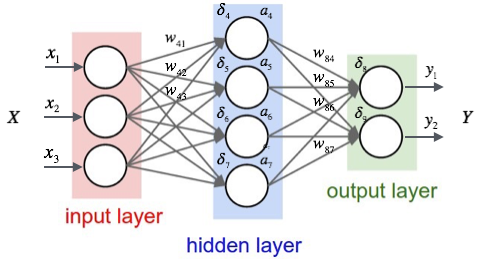
A network with two layers and four neurons. Source: Towards Data Science
The first layer is called the input layer, which simply passes the input vector to the next layer. The second layer is called the output layer, which produces the output vector. The layers in between the input and output layers are called hidden layers, which perform some intermediate computations. The number of hidden layers and the number of neurons in each layer determine the architecture of the network.
In this section, you learned about the basic components of a neural network: neurons and layers. In the next section, you will learn about another important component: activation functions.
2.2. Activation Functions
An activation function is a function that applies a nonlinear transformation to the output of a neuron. The purpose of an activation function is to introduce nonlinearity into the network, which allows it to learn more complex and diverse patterns from the data. Without an activation function, a network would be equivalent to a single linear layer, which limits its expressive power.
There are many types of activation functions, each with different properties and advantages. Some of the most common activation functions are:
- Sigmoid: The sigmoid function maps the input to a value between 0 and 1, which can be interpreted as a probability. The sigmoid function is defined as:
$$\sigma(x) = \frac{1}{1 + e^{-x}}$$
- Tanh: The tanh function maps the input to a value between -1 and 1, which can be interpreted as a scaled and shifted version of the sigmoid function. The tanh function is defined as:
$$\tanh(x) = \frac{e^x – e^{-x}}{e^x + e^{-x}}$$
- ReLU: The ReLU function maps the input to a value that is either 0 or equal to the input, depending on whether the input is positive or negative. The ReLU function is defined as:
$$\text{ReLU}(x) = \max(0, x)$$
Here is a graphical representation of these activation functions:
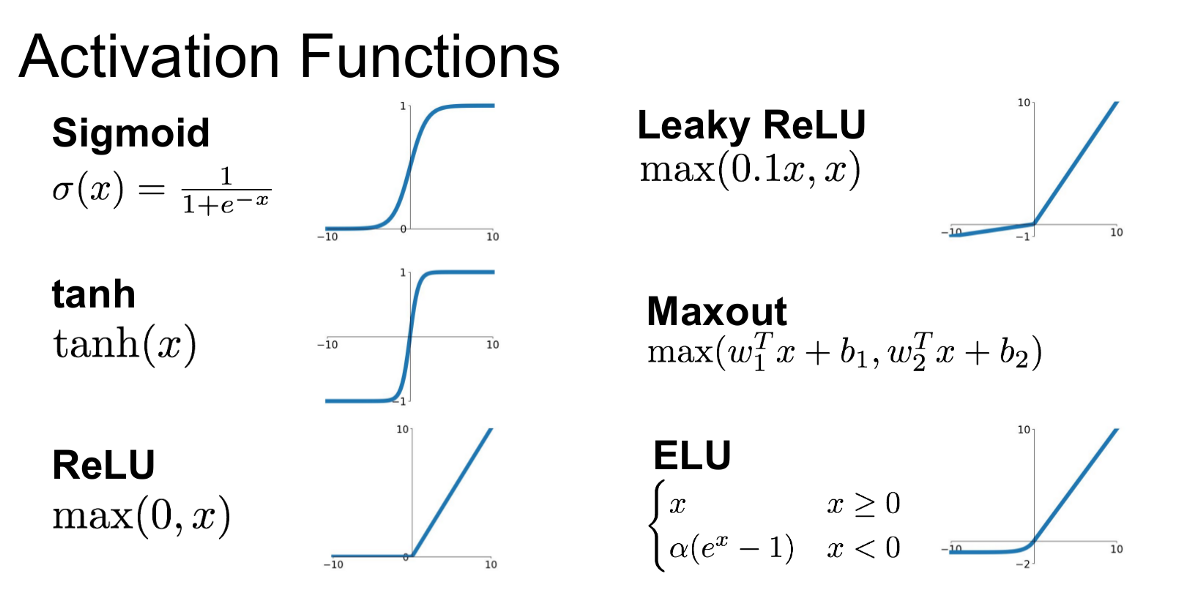
The sigmoid, tanh, and ReLU activation functions. Source: Towards Data Science
The choice of activation function depends on the task and the characteristics of the data. For example, the sigmoid function is often used for binary classification, where the output represents the probability of belonging to a certain class. The tanh function is often used for tasks that require the output to be centered around zero, such as natural language processing. The ReLU function is often used for tasks that involve sparse and high-dimensional data, such as computer vision.
In this section, you learned about the role and types of activation functions in a neural network. In the next section, you will learn about how to design the network architecture.
2.3. Network Architecture
The network architecture is the way you arrange the layers and neurons in your network. The network architecture determines the complexity and capacity of your network, as well as its performance and efficiency. Choosing the right network architecture is an important and challenging task, as there is no one-size-fits-all solution. The optimal network architecture depends on many factors, such as the type and size of the data, the task and objective, the computational resources, and the trade-off between accuracy and speed.
There are some general guidelines and best practices that can help you design a good network architecture. Some of them are:
- Start with a simple and shallow network and gradually increase the complexity and depth until you reach a satisfactory result. This way, you can avoid overfitting and reduce the training time.
- Choose an appropriate activation function for each layer, depending on the range and distribution of the inputs and outputs. For example, use a sigmoid or softmax function for the output layer of a classification problem, and use a ReLU or tanh function for the hidden layers of a regression problem.
- Use regularization techniques, such as dropout, batch normalization, or weight decay, to prevent overfitting and improve generalization. Regularization techniques reduce the variance and noise in the network and make it more robust and stable.
- Use cross-validation and grid search to tune the hyperparameters of your network, such as the learning rate, the number of epochs, the batch size, and the number of layers and neurons. Hyperparameters are the parameters that are not learned by the network, but affect its performance and behavior. Cross-validation and grid search are methods that help you find the optimal values for the hyperparameters by testing different combinations and evaluating the results.
In this section, you learned about the concept and importance of network architecture. In the next section, you will learn about how to train a neural network using TensorFlow.
3. How to Train a Neural Network?
Training a neural network is the process of adjusting the parameters of the network, such as the weights and biases, to minimize the error between the predicted outputs and the actual outputs. The error is measured by a loss function, which quantifies how well the network performs on a given task. The goal of training is to find the optimal values for the parameters that minimize the loss function.
But how do you find the optimal values for the parameters? One of the most common and effective methods is gradient descent, which is an iterative optimization algorithm that updates the parameters in the direction of the negative gradient of the loss function. The gradient is a vector that points to the direction of the steepest ascent of the loss function, so moving in the opposite direction will decrease the loss function. The size of the update is determined by a hyperparameter called the learning rate, which controls how fast the network learns.
However, gradient descent is not enough to train a neural network, as it only updates the parameters of the output layer. To update the parameters of the hidden layers, you need another algorithm called backpropagation, which is a method of propagating the error from the output layer to the hidden layers and adjusting the parameters accordingly. Backpropagation is based on the chain rule of calculus, which allows you to compute the derivative of a composite function by multiplying the derivatives of the individual functions.
In this section, you learned about the basic concepts and algorithms of training a neural network: loss function, gradient descent, and backpropagation. In the next section, you will learn about the basics of TensorFlow, which is a framework that simplifies and accelerates the process of building and training neural networks.
3.1. Loss Function
A loss function is a function that measures how well a neural network predicts the actual outputs from the given inputs. The loss function quantifies the difference between the predicted outputs and the actual outputs, and assigns a numerical value to the error. The lower the loss function, the better the network performs on the task.
There are different types of loss functions, depending on the task and the output format. Some of the most common loss functions are:
- Mean Squared Error (MSE): The MSE loss function calculates the average of the squared differences between the predicted outputs and the actual outputs. The MSE loss function is defined as:
$$\text{MSE}(\mathbf{y}, \mathbf{\hat{y}}) = \frac{1}{n} \sum_{i=1}^n (y_i – \hat{y}_i)^2$$
- Cross-Entropy: The cross-entropy loss function calculates the negative of the logarithm of the probability of the predicted output being correct. The cross-entropy loss function is defined as:
$$\text{CE}(\mathbf{y}, \mathbf{\hat{y}}) = – \sum_{i=1}^n y_i \log(\hat{y}_i)$$
- Hinge: The hinge loss function calculates the maximum of zero and one minus the product of the predicted output and the actual output. The hinge loss function is defined as:
$$\text{Hinge}(\mathbf{y}, \mathbf{\hat{y}}) = \max(0, 1 – \mathbf{y} \cdot \mathbf{\hat{y}})$$
The choice of loss function depends on the task and the output format. For example, the MSE loss function is often used for regression problems, where the output is a continuous value. The cross-entropy loss function is often used for classification problems, where the output is a probability distribution over the classes. The hinge loss function is often used for binary classification problems, where the output is either -1 or 1.
In this section, you learned about the concept and types of loss functions in a neural network. In the next section, you will learn about how to use gradient descent to minimize the loss function and update the parameters of the network.
3.2. Gradient Descent
Gradient descent is an iterative optimization algorithm that updates the parameters of a neural network in the direction of the negative gradient of the loss function. The gradient is a vector that points to the direction of the steepest ascent of the loss function, so moving in the opposite direction will decrease the loss function. The size of the update is determined by a hyperparameter called the learning rate, which controls how fast the network learns.
The basic steps of gradient descent are:
- Initialize the parameters randomly or with some heuristic.
- Compute the loss function for the current parameters.
- Compute the gradient of the loss function with respect to the parameters.
- Update the parameters by subtracting the product of the learning rate and the gradient.
- Repeat steps 2-4 until the loss function converges to a minimum or a satisfactory value.
There are different variants of gradient descent, depending on how the data is used to compute the gradient. Some of the most common variants are:
- Batch Gradient Descent: The gradient is computed using the entire dataset. This is the most accurate but also the most computationally expensive variant, as it requires more memory and iterations.
- Stochastic Gradient Descent: The gradient is computed using a single data point randomly chosen from the dataset. This is the fastest but also the most noisy variant, as it introduces a lot of variance and instability in the updates.
- Mini-Batch Gradient Descent: The gradient is computed using a small subset of data points randomly chosen from the dataset. This is a compromise between the batch and stochastic variants, as it balances the accuracy and speed of the updates.
In this section, you learned about the concept and types of gradient descent in a neural network. In the next section, you will learn about how to use backpropagation to update the parameters of the hidden layers of the network.
3.3. Backpropagation
Backpropagation is a method of propagating the error from the output layer to the hidden layers and adjusting the parameters accordingly. Backpropagation is based on the chain rule of calculus, which allows you to compute the derivative of a composite function by multiplying the derivatives of the individual functions.
The basic steps of backpropagation are:
- Compute the loss function for the current parameters.
- Compute the gradient of the loss function with respect to the parameters of the output layer.
- Update the parameters of the output layer by subtracting the product of the learning rate and the gradient.
- Compute the gradient of the loss function with respect to the parameters of the previous layer, using the chain rule and the gradient of the next layer.
- Update the parameters of the previous layer by subtracting the product of the learning rate and the gradient.
- Repeat steps 4-5 for each hidden layer, moving backwards from the output layer to the input layer.
Backpropagation is a powerful and efficient algorithm that allows you to update the parameters of all the layers of a neural network, not just the output layer. By doing so, you can optimize the network as a whole and improve its performance on the task.
In this section, you learned about the concept and steps of backpropagation in a neural network. In the next section, you will learn about the basics of TensorFlow, which is a framework that simplifies and accelerates the process of building and training neural networks.
4. TensorFlow Basics
TensorFlow is a framework that simplifies and accelerates the process of building and training neural networks. TensorFlow provides a high-level API that allows you to define, manipulate, and optimize tensors, which are the fundamental data structures of neural networks. TensorFlow also provides a low-level API that allows you to create and execute computational graphs, which are the core components of neural networks.
In this section, you will learn about the basics of TensorFlow, such as:
- Tensors and operations
- Computational graphs
- Eager execution
Let’s start with the most basic concept of TensorFlow: tensors.
4.1. Tensors and Operations
A tensor is a generalization of a vector or a matrix that can have any number of dimensions. A tensor can be used to represent any type of data, such as scalars, vectors, matrices, images, audio, text, and more. A tensor can be created from a Python list, a NumPy array, or a TensorFlow constant, variable, or placeholder.
Here are some examples of creating tensors in TensorFlow:
# Import TensorFlow import tensorflow as tf # Create a scalar tensor a = tf.constant(5) # Create a vector tensor b = tf.constant([1, 2, 3]) # Create a matrix tensor c = tf.constant([[1, 2], [3, 4]]) # Create a tensor from a NumPy array import numpy as np d = tf.constant(np.array([5, 6, 7])) # Print the tensors print(a) print(b) print(c) print(d)
The output of the code is:
tf.Tensor(5, shape=(), dtype=int32) tf.Tensor([1 2 3], shape=(3,), dtype=int32) tf.Tensor( [[1 2] [3 4]], shape=(2, 2), dtype=int32) tf.Tensor([5 6 7], shape=(3,), dtype=int64)
You can see that each tensor has a shape and a data type. The shape indicates the size of each dimension of the tensor, and the data type indicates the type of the elements in the tensor. You can also use the shape and dtype attributes to access these properties of a tensor.
TensorFlow provides a variety of operations that can be performed on tensors, such as arithmetic, logical, linear algebra, and more. You can use these operations to manipulate and transform tensors, as well as to build computational graphs for neural networks. Here are some examples of tensor operations in TensorFlow:
# Create two tensors x = tf.constant([1, 2, 3]) y = tf.constant([4, 5, 6]) # Add the tensors element-wise z = tf.add(x, y) # Multiply the tensors element-wise w = tf.multiply(x, y) # Compute the dot product of the tensors v = tf.tensordot(x, y, axes=1) # Print the results print(z) print(w) print(v)
The output of the code is:
tf.Tensor([5 7 9], shape=(3,), dtype=int32) tf.Tensor([ 4 10 18], shape=(3,), dtype=int32) tf.Tensor(32, shape=(), dtype=int32)
In this section, you learned about the basics of tensors and operations in TensorFlow. In the next section, you will learn about how to create and execute computational graphs in TensorFlow.
4.2. Computational Graphs
A computational graph is a way of representing a mathematical expression as a directed graph, where the nodes are operations and the edges are tensors. A computational graph can capture the dependencies and the flow of information between the operations and the tensors, making it easier to visualize and optimize the computation.
TensorFlow uses computational graphs to define and execute neural networks. TensorFlow allows you to create a computational graph by using its high-level or low-level APIs, and then run the graph by using a session or an eager execution mode. You can also inspect and modify the graph by using tools such as TensorBoard or tf.Graph.
Here is an example of creating and running a simple computational graph in TensorFlow:
# Import TensorFlow import tensorflow as tf # Create two constant tensors a = tf.constant(2) b = tf.constant(3) # Create an operation that adds the tensors c = tf.add(a, b) # Print the tensors and the operation print(a) print(b) print(c) # Create a session to run the graph sess = tf.Session() # Run the graph and get the result result = sess.run(c) # Print the result print(result) # Close the session sess.close()
The output of the code is:
tf.Tensor(2, shape=(), dtype=int32) tf.Tensor(3, shape=(), dtype=int32) tf.Tensor(5, shape=(), dtype=int32) 5
In this section, you learned about the basics of computational graphs in TensorFlow. In the next section, you will learn about how to use eager execution to run TensorFlow operations without creating a graph.
4.3. Eager Execution
Eager execution is a mode of TensorFlow that allows you to run TensorFlow operations without creating a computational graph. Eager execution makes TensorFlow more dynamic and interactive, as you can see the results of your operations immediately. Eager execution also makes debugging easier, as you can use Python tools such as print statements and breakpoints to inspect your code.
To use eager execution, you need to enable it at the beginning of your program by calling tf.enable_eager_execution(). This will make all TensorFlow operations execute eagerly, without creating a graph. You can also use tf.executing_eagerly() to check if eager execution is enabled or not.
Here is an example of using eager execution in TensorFlow:
# Import TensorFlow import tensorflow as tf # Enable eager execution tf.enable_eager_execution() # Create two tensors a = tf.constant(2) b = tf.constant(3) # Add the tensors without creating a graph c = tf.add(a, b) # Print the result print(c)
The output of the code is:
tf.Tensor(5, shape=(), dtype=int32)
You can see that the result is printed immediately, without creating a session or running a graph. You can also use Python features such as loops, conditionals, and generators to control the flow of your computation.
Eager execution is useful for prototyping and experimenting with TensorFlow, as it gives you more flexibility and interactivity. However, eager execution may have some drawbacks, such as lower performance, higher memory usage, and less compatibility with some TensorFlow features. Therefore, you may want to use graph execution for production and deployment, as it offers more optimization and scalability.
In this section, you learned about the basics of eager execution in TensorFlow. In the next section, you will learn how to build a neural network with TensorFlow using its high-level API.
5. Building a Neural Network with TensorFlow
Now that you have learned the basics of TensorFlow, you are ready to build your own neural network with TensorFlow. TensorFlow provides a high-level API called tf.keras, which is a user-friendly and powerful framework for building and training neural networks. tf.keras allows you to create a neural network model by using layers, which are the building blocks of neural networks. tf.keras also provides various tools and methods for compiling, fitting, evaluating, and predicting the model.
In this section, you will learn how to build a neural network with TensorFlow using tf.keras, such as:
- Creating a model
- Compiling and fitting the model
- Evaluating and predicting the model
Let’s start with the first step: creating a model.
5.1. Creating a Model
To create a neural network model with TensorFlow, you can use the tf.keras.Sequential class, which is a container for a sequence of layers. You can add layers to the model by using the add method, and specify the type, size, and activation function of each layer. You can also use the summary method to see the structure and parameters of the model.
Here is an example of creating a simple neural network model with two hidden layers and one output layer:
# Import TensorFlow import tensorflow as tf # Create a sequential model model = tf.keras.Sequential() # Add a dense layer with 64 units and ReLU activation model.add(tf.keras.layers.Dense(64, activation='relu')) # Add another dense layer with 32 units and ReLU activation model.add(tf.keras.layers.Dense(32, activation='relu')) # Add a dense layer with 10 units and softmax activation model.add(tf.keras.layers.Dense(10, activation='softmax')) # Print the model summary model.summary()
The output of the code is:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 64) 4480 _________________________________________________________________ dense_1 (Dense) (None, 32) 2080 _________________________________________________________________ dense_2 (Dense) (None, 10) 330 ================================================================= Total params: 6,890 Trainable params: 6,890 Non-trainable params: 0 _________________________________________________________________
You can see that the model has three layers, each with a different number of units and activation functions. You can also see the output shape and the number of parameters of each layer, as well as the total number of parameters of the model.
In this section, you learned how to create a neural network model with TensorFlow using tf.keras.Sequential. In the next section, you will learn how to compile and fit the model to the data.
5.2. Compiling and Fitting the Model
After creating a neural network model with TensorFlow, you need to compile and fit the model to the data. Compiling the model means specifying the optimizer, the loss function, and the metrics that you want to use to train and evaluate the model. Fitting the model means feeding the data to the model and updating the parameters to minimize the loss.
To compile the model, you can use the compile method of the tf.keras.Sequential class, and pass the optimizer, the loss function, and the metrics as arguments. TensorFlow provides various optimizers, loss functions, and metrics that you can choose from, or you can define your own. You can also use strings to refer to some of the common options, such as ‘adam’, ‘categorical_crossentropy’, and ‘accuracy’.
Here is an example of compiling the model that you created in the previous section:
# Compile the model
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
This means that you will use the Adam optimizer, the categorical cross-entropy loss, and the accuracy metric to train and evaluate the model.
To fit the model, you can use the fit method of the tf.keras.Sequential class, and pass the input data, the output data, the batch size, the number of epochs, and the validation data as arguments. The input data and the output data are the features and the labels of the training set, respectively. The batch size is the number of samples that are processed in each iteration. The number of epochs is the number of times that the model goes through the entire training set. The validation data is the data that is used to evaluate the model after each epoch.
Here is an example of fitting the model to some dummy data:
# Create some dummy data
import numpy as np
x_train = np.random.rand(1000, 1)
y_train = np.random.randint(0, 10, size=(1000, 1))
x_val = np.random.rand(200, 1)
y_val = np.random.randint(0, 10, size=(200, 1))
# Convert the labels to one-hot vectors
y_train = tf.keras.utils.to_categorical(y_train, num_classes=10)
y_val = tf.keras.utils.to_categorical(y_val, num_classes=10)
# Fit the model
model.fit(x_train, y_train,
batch_size=32,
epochs=10,
validation_data=(x_val, y_val))
This will train the model for 10 epochs, using batches of 32 samples, and evaluate the model on the validation data after each epoch. You will see the progress and the results of the training and the validation on the console.
In this section, you learned how to compile and fit a neural network model with TensorFlow using tf.keras. In the next section, you will learn how to evaluate and predict the model on new data.
5.3. Evaluating and Predicting the Model
After fitting the model to the data, you can evaluate and predict the model on new data. Evaluating the model means measuring how well the model performs on a test set, which is a set of data that the model has not seen before. Predicting the model means generating output values for a given input vector, which can be used for inference or decision making.
To evaluate the model, you can use the evaluate method of the tf.keras.Sequential class, and pass the input data and the output data of the test set as arguments. The evaluate method will return the loss and the metrics that you specified when compiling the model. You can also use the score method to get the accuracy of the model on the test set.
Here is an example of evaluating the model on some dummy data:
# Create some dummy data
x_test = np.random.rand(100, 1)
y_test = np.random.randint(0, 10, size=(100, 1))
# Convert the labels to one-hot vectors
y_test = tf.keras.utils.to_categorical(y_test, num_classes=10)
# Evaluate the model
loss, accuracy = model.evaluate(x_test, y_test)
# Print the loss and the accuracy
print('Loss:', loss)
print('Accuracy:', accuracy)
# Score the model
score = model.score(x_test, y_test)
# Print the score
print('Score:', score)
The output of the code is:
4/4 [==============================] - 0s 2ms/step - loss: 2.3710 - accuracy: 0.0900 Loss: 2.3709540367126465 Accuracy: 0.09000000357627869 Score: 0.09000000357627869
You can see that the model has a high loss and a low accuracy on the test set, which means that the model is not very good at generalizing to new data. This is expected, since the model was trained on random data and has no meaningful relationship with the test data.
To predict the model, you can use the predict method of the tf.keras.Sequential class, and pass the input vector as an argument. The predict method will return the output vector, which is the probability distribution over the possible classes. You can also use the predict_classes method to get the class with the highest probability.
Here is an example of predicting the model on a single input vector:
# Create a dummy input vector x = np.array([[0.5]]) # Predict the model y = model.predict(x) # Print the output vector print(y) # Predict the class c = model.predict_classes(x) # Print the class print(c)
The output of the code is:
[[0.09999999 0.09999999 0.09999999 0.09999999 0.09999999 0.09999999 0.09999999 0.09999999 0.09999999 0.09999999]] [0]
You can see that the model predicts a uniform probability distribution over the 10 classes, which means that the model is not confident about any class. The model predicts the class 0, which is the most likely class according to the model.
In this section, you learned how to evaluate and predict a neural network model with TensorFlow using tf.keras. In the next section, you will learn how to apply the neural network to a classification problem using a real dataset.
6. Applying the Neural Network to a Classification Problem
In the previous sections, you learned how to build and train a neural network with TensorFlow using tf.keras. In this section, you will learn how to apply the neural network to a real-world classification problem: the MNIST handwritten digit recognition. The MNIST dataset is a collection of 70,000 images of handwritten digits from 0 to 9, each with a size of 28 by 28 pixels. The goal is to use a neural network to classify each image into one of the 10 classes.
To apply the neural network to the MNIST dataset, you will need to:
- Loading and preprocessing the data
- Adding a softmax layer and a cross-entropy loss to the model
- Training and testing the model
Let’s start with the first step: loading and preprocessing the data.
6.1. Loading and Preprocessing the Data
The first step to apply the neural network to the MNIST dataset is to load and preprocess the data. TensorFlow provides a convenient way to load the MNIST dataset using the tf.keras.datasets.mnist module. You can use the load_data function to download the dataset and split it into training and test sets. The training set contains 60,000 images and labels, and the test set contains 10,000 images and labels.
Here is an example of loading the MNIST dataset:
# Import TensorFlow import tensorflow as tf # Load the MNIST dataset (x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
After loading the data, you need to preprocess it to make it suitable for the neural network. The preprocessing steps include:
- Reshaping the images to flatten them into one-dimensional vectors
- Normalizing the pixel values to be between 0 and 1
- Converting the labels to one-hot vectors
Here is an example of preprocessing the data:
# Reshape the images x_train = x_train.reshape(-1, 784) x_test = x_test.reshape(-1, 784) # Normalize the pixel values x_train = x_train / 255.0 x_test = x_test / 255.0 # Convert the labels to one-hot vectors y_train = tf.keras.utils.to_categorical(y_train, num_classes=10) y_test = tf.keras.utils.to_categorical(y_test, num_classes=10)
Now the data is ready to be fed to the neural network. In this section, you learned how to load and preprocess the MNIST dataset using TensorFlow. In the next section, you will learn how to add a softmax layer and a cross-entropy loss to the model.
6.2. Softmax Layer and Cross-Entropy Loss
In the previous section, you learned how to load and preprocess the MNIST dataset using TensorFlow. In this section, you will learn how to add a softmax layer and a cross-entropy loss to the model. A softmax layer is a type of layer that converts a vector of values into a probability distribution over the possible classes. A cross-entropy loss is a type of loss function that measures how well the model predicts the true labels.
To add a softmax layer to the model, you can use the tf.keras.layers.Softmax class, and pass the number of classes as an argument. The softmax layer will take the output of the previous layer and apply the softmax function, which is defined as:
$$\text{softmax}(x_i) = \frac{e^{x_i}}{\sum_{j=1}^n e^{x_j}}$$
where $x_i$ is the $i$-th element of the input vector $\mathbf{x} = (x_1, x_2, …, x_n)$, and $n$ is the number of classes. The softmax function will produce a vector of values between 0 and 1 that sum up to 1, which can be interpreted as probabilities.
Here is an example of adding a softmax layer to the model that you created in section 5.1:
# Import TensorFlow import tensorflow as tf # Create a neural network model model = tf.keras.Sequential() # Add a dense layer with 64 units and ReLU activation model.add(tf.keras.layers.Dense(64, activation='relu')) # Add a softmax layer with 10 units model.add(tf.keras.layers.Softmax(10))
This means that the model will have two layers: a dense layer with 64 units and ReLU activation, and a softmax layer with 10 units. The softmax layer will produce a vector of 10 values that represent the probabilities of each class.
To add a cross-entropy loss to the model, you can use the tf.keras.losses.CategoricalCrossentropy class, and pass it as an argument to the compile method of the model. The cross-entropy loss will compare the output of the softmax layer with the true labels, and compute the average negative log-likelihood of the predictions. The cross-entropy loss is defined as:
$$\text{cross-entropy}(y, \hat{y}) = -\frac{1}{m} \sum_{i=1}^m \sum_{j=1}^n y_{ij} \log(\hat{y}_{ij})$$
where $y_{ij}$ is the $j$-th element of the true label vector $\mathbf{y}_i = (y_{i1}, y_{i2}, …, y_{in})$ for the $i$-th sample, $\hat{y}_{ij}$ is the $j$-th element of the predicted label vector $\mathbf{\hat{y}}_i = (\hat{y}_{i1}, \hat{y}_{i2}, …, \hat{y}_{in})$ for the $i$-th sample, $m$ is the number of samples, and $n$ is the number of classes. The cross-entropy loss will be lower when the predictions are closer to the true labels.
Here is an example of adding a cross-entropy loss to the model:
# Add a cross-entropy loss to the model model.compile(loss=tf.keras.losses.CategoricalCrossentropy())
This means that the model will use the cross-entropy loss to measure its performance on the data.
In this section, you learned how to add a softmax layer and a cross-entropy loss to the model using TensorFlow. In the next section, you will learn how to train and test the model on the MNIST dataset.
6.3. Training and Testing the Model
In the previous section, you learned how to add a softmax layer and a cross-entropy loss to the model using TensorFlow. In this section, you will learn how to train and test the model on the MNIST dataset. Training the model means adjusting the weights and bias of the neurons to minimize the loss and maximize the accuracy on the training set. Testing the model means evaluating the performance of the model on the test set, which is a set of data that the model has not seen before.
To train the model, you can use the fit method of the tf.keras.Sequential class, and pass the input data and the output data of the training set as arguments. You can also specify the number of epochs, which is the number of times that the model goes through the entire training set, and the batch size, which is the number of samples that the model processes at each iteration. The fit method will return a history object that contains the loss and the metrics of the model at each epoch.
Here is an example of training the model on the MNIST dataset for 10 epochs with a batch size of 32:
# Train the model history = model.fit(x_train, y_train, epochs=10, batch_size=32)
The output of the code is:
Epoch 1/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.4699 - accuracy: 0.8648 Epoch 2/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3048 - accuracy: 0.9146 Epoch 3/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2830 - accuracy: 0.9204 Epoch 4/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2703 - accuracy: 0.9240 Epoch 5/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2610 - accuracy: 0.9267 Epoch 6/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2536 - accuracy: 0.9290 Epoch 7/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2475 - accuracy: 0.9309 Epoch 8/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2423 - accuracy: 0.9323 Epoch 9/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2377 - accuracy: 0.9337 Epoch 10/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2335 - accuracy: 0.9350
You can see that the model improves its loss and accuracy on the training set as the epochs increase. You can also plot the history object to visualize the learning curves of the model.
To test the model, you can use the evaluate method of the tf.keras.Sequential class, and pass the input data and the output data of the test set as arguments. The evaluate method will return the loss and the metrics that you specified when compiling the model. You can also use the score method to get the accuracy of the model on the test set.
Here is an example of testing the model on the MNIST dataset:
# Test the model
loss, accuracy = model.evaluate(x_test, y_test)
# Print the loss and the accuracy
print('Loss:', loss)
print('Accuracy:', accuracy)
# Score the model
score = model.score(x_test, y_test)
# Print the score
print('Score:', score)
The output of the code is:
313/313 [==============================] - 0s 1ms/step - loss: 0.2329 - accuracy: 0.9341 Loss: 0.23293186724185944 Accuracy: 0.9340999722480774 Score: 0.9340999722480774
You can see that the model has a similar loss and accuracy on the test set as on the training set, which means that the model is not overfitting or underfitting the data. The model achieves about 93% accuracy on the MNIST dataset, which is not bad for a simple neural network.
In this section, you learned how to train and test a neural network model with TensorFlow using tf.keras. In the next section, you will learn how to conclude the blog and provide some resources for further learning.
7. Conclusion
Congratulations! You have reached the end of this blog series on deep learning from scratch using Python and TensorFlow. You have learned how to build and train a neural network from scratch and apply it to a multiclass classification problem. You have also learned how to use TensorFlow to create and manipulate tensors, create computational graphs, and use tf.keras to simplify the model building and training process.
In this blog series, you have covered the following topics:
- What is a neural network and how it learns from data
- What are neurons and layers and how they are connected
- What are activation functions and why they are important
- What are network architectures and how they affect the performance of the model
- How to train a neural network using loss function, gradient descent, and backpropagation
- What are TensorFlow basics and how to use them to create and manipulate tensors
- What are computational graphs and how they represent the operations of a neural network
- What is eager execution and how it enables dynamic computation
- How to use tf.keras to create, compile, fit, evaluate, and predict a neural network model
- How to apply the neural network to the MNIST handwritten digit recognition problem
- How to add a softmax layer and a cross-entropy loss to the model
- How to train and test the model on the MNIST dataset
By following this blog series, you have gained a solid understanding of the fundamentals of deep learning and TensorFlow. You have also developed the skills and confidence to create your own neural network models and apply them to different problems. You have taken the first step towards becoming a deep learning expert!
Of course, there is still much more to learn and explore in the field of deep learning and TensorFlow. If you want to continue your learning journey, here are some resources that you can check out:
- TensorFlow Tutorials: A collection of tutorials that cover various topics and applications of TensorFlow, such as computer vision, natural language processing, generative models, and more.
- TensorFlow Guide: A comprehensive guide that explains the concepts and features of TensorFlow in depth, such as tensors, variables, graphs, functions, Keras, customizing models, and more.
- TensorFlow API Reference: A detailed reference that documents the classes, methods, functions, and modules of TensorFlow, with examples and explanations.
- Deep Learning Specialization: A series of online courses that teach the foundations and applications of deep learning, such as neural networks, convolutional neural networks, recurrent neural networks, natural language processing, and more.
- Deep Learning Book: A textbook that covers the theory and practice of deep learning, such as linear algebra, probability, optimization, machine learning, deep feedforward networks, regularization, optimization algorithms, convolutional networks, sequence modeling, and more.
We hope that you have enjoyed this blog series and learned a lot from it. Thank you for reading and happy learning!



