
1. Introduction
Reinforcement learning is a branch of machine learning that deals with learning from actions and rewards. It is inspired by how humans and animals learn from trial and error, and how they adapt to their environment based on feedback.
In reinforcement learning, an agent interacts with an environment and learns from its own experience. The agent does not have a predefined set of rules or instructions, but rather learns by doing. The agent receives rewards or penalties for its actions, and tries to maximize its total reward over time.
Reinforcement learning has many applications in various domains, such as robotics, gaming, self-driving cars, and more. It can solve complex problems that require dynamic and adaptive behavior, and that are not easily solved by traditional methods.
In this blog, you will learn how to use reinforcement learning and Q-learning to train agents that can learn from their own actions and rewards. You will learn the basics of reinforcement learning, how Q-learning works, and how to implement it with Keras and TensorFlow. You will also explore some advanced topics in reinforcement learning and Q-learning, such as exploration vs exploitation, deep Q-learning, and policy gradient methods.
By the end of this blog, you will have a solid understanding of reinforcement learning and Q-learning, and you will be able to apply them to your own projects.
Are you ready to dive into the world of reinforcement learning and Q-learning? Let’s get started!
2. Reinforcement Learning Basics
In this section, you will learn the basics of reinforcement learning, one of the most exciting and powerful branches of machine learning. You will learn what reinforcement learning is, how it differs from other types of machine learning, and what are the main components and challenges of reinforcement learning. You will also learn about the different types of reinforcement learning algorithms, and how they can be classified based on their properties and characteristics.
But first, let’s start with a simple question: What is reinforcement learning?
What is Reinforcement Learning?
Reinforcement learning is a type of machine learning that deals with learning from actions and rewards. It is inspired by how humans and animals learn from trial and error, and how they adapt to their environment based on feedback.
In reinforcement learning, an agent interacts with an environment and learns from its own experience. The agent does not have a predefined set of rules or instructions, but rather learns by doing. The agent receives rewards or penalties for its actions, and tries to maximize its total reward over time.
For example, imagine that you are playing a video game, such as Super Mario. In this game, you are the agent, and the game world is the environment. You can perform various actions, such as moving left, right, up, or down, and jumping or shooting. For each action, you receive a reward or a penalty, such as gaining or losing points, coins, lives, or health. Your goal is to learn the best actions that will lead you to the highest score and the end of the game.
This is an example of reinforcement learning, where you learn from your own actions and rewards, and you try to optimize your behavior based on feedback.
The Reinforcement Learning Problem
The reinforcement learning problem can be formally defined as a Markov decision process (MDP), which consists of four main components:
- Agent: The learner or decision-maker, who interacts with the environment and performs actions.
- Environment: The system or world that the agent interacts with, and that provides feedback to the agent.
- Action: The choice that the agent makes at each time step, which affects the state of the environment and the reward that the agent receives.
- Reward: The feedback that the agent receives from the environment for each action, which indicates how good or bad the action was.
The goal of the agent is to learn a policy, which is a function that maps each state of the environment to an action that the agent should take. The policy should maximize the expected return, which is the total amount of reward that the agent can expect to receive over time, or over an episode (a sequence of actions and rewards that ends when the agent reaches a terminal state).
The reinforcement learning problem can be illustrated by the following diagram:

The reinforcement learning problem is challenging for several reasons, such as:
- The agent has to deal with uncertainty, as the environment may be stochastic (random) or partially observable (incomplete information).
- The agent has to balance between exploration and exploitation, as it has to try new actions to discover better ones, but also use the best actions that it has learned so far to maximize its reward.
- The agent has to cope with delayed rewards, as the consequences of its actions may not be immediate, but may depend on future actions and states.
- The agent has to handle large and complex state and action spaces, as the environment may have many possible states and actions, which may be continuous or high-dimensional.
These challenges make reinforcement learning a difficult but fascinating problem to solve, and require different types of algorithms and techniques.
Types of Reinforcement Learning Algorithms
There are many different types of reinforcement learning algorithms, which can be classified based on various criteria, such as:
- Model-based vs model-free: Model-based algorithms use a model of the environment, which is a function that predicts the next state and reward given the current state and action. Model-free algorithms do not use a model of the environment, but learn directly from experience.
- Value-based vs policy-based: Value-based algorithms learn a value function, which is a function that estimates the expected return for each state or state-action pair. Policy-based algorithms learn a policy function, which is a function that specifies the action to take for each state.
- On-policy vs off-policy: On-policy algorithms learn from the data generated by the current policy, which means that they explore and exploit at the same time. Off-policy algorithms learn from the data generated by a different policy, which means that they can separate exploration and exploitation.
Some of the most popular and widely used reinforcement learning algorithms are:
- Q-learning: A model-free, value-based, off-policy algorithm that learns a Q-function, which is a function that estimates the expected return for each state-action pair. Q-learning is one of the simplest but most powerful reinforcement learning algorithms, and it will be the main focus of this blog.
- SARSA: A model-free, value-based, on-policy algorithm that learns a Q-function, similar to Q-learning, but with a different update rule that takes into account the current policy.
- Monte Carlo methods: A model-free, value-based or policy-based, on-policy or off-policy algorithm that learns from complete episodes, rather than from individual steps. Monte Carlo methods use sampling and averaging to estimate the value function or the policy function.
- Temporal difference methods: A model-free, value-based or policy-based, on-policy or off-policy algorithm that learns from incomplete episodes, rather than from complete episodes. Temporal difference methods use bootstrapping and updating to estimate the value function or the policy function.
- Actor-critic methods: A model-free, policy-based, on-policy or off-policy algorithm that combines the advantages of value-based and policy-based methods. Actor-critic methods use two functions: an actor, which is a policy function that specifies the action to take for each state, and a critic, which is a value function that evaluates the action taken by the actor.
- Deep reinforcement learning methods: A model-free, value-based or policy-based, off-policy algorithm that uses deep neural networks to approximate the value function or the policy function. Deep reinforcement learning methods can handle large and complex state and action spaces, and have achieved remarkable results in various domains, such as Atari games, Go, and chess.
These are some of the most common types of reinforcement learning algorithms, but there are many more, and new ones are being developed and improved constantly. Reinforcement learning is a very active and exciting field of research, and there is still a lot to discover and learn.
In the next section, you will learn more about Q-learning, one of the most simple but powerful reinforcement learning algorithms, and how it works.
2.1. What is Reinforcement Learning?
Reinforcement learning is a type of machine learning that deals with learning from actions and rewards. It is inspired by how humans and animals learn from trial and error, and how they adapt to their environment based on feedback.
In reinforcement learning, an agent interacts with an environment and learns from its own experience. The agent does not have a predefined set of rules or instructions, but rather learns by doing. The agent receives rewards or penalties for its actions, and tries to maximize its total reward over time.
For example, imagine that you are playing a video game, such as Super Mario. In this game, you are the agent, and the game world is the environment. You can perform various actions, such as moving left, right, up, or down, and jumping or shooting. For each action, you receive a reward or a penalty, such as gaining or losing points, coins, lives, or health. Your goal is to learn the best actions that will lead you to the highest score and the end of the game.
This is an example of reinforcement learning, where you learn from your own actions and rewards, and you try to optimize your behavior based on feedback.
But what makes reinforcement learning different from other types of machine learning, such as supervised learning or unsupervised learning? And what are the main components and challenges of reinforcement learning? Let’s find out in the next section.
2.2. The Reinforcement Learning Problem
The reinforcement learning problem can be formally defined as a Markov decision process (MDP), which consists of four main components:
- Agent: The learner or decision-maker, who interacts with the environment and performs actions.
- Environment: The system or world that the agent interacts with, and that provides feedback to the agent.
- Action: The choice that the agent makes at each time step, which affects the state of the environment and the reward that the agent receives.
- Reward: The feedback that the agent receives from the environment for each action, which indicates how good or bad the action was.
The goal of the agent is to learn a policy, which is a function that maps each state of the environment to an action that the agent should take. The policy should maximize the expected return, which is the total amount of reward that the agent can expect to receive over time, or over an episode (a sequence of actions and rewards that ends when the agent reaches a terminal state).
The reinforcement learning problem can be illustrated by the following diagram:
The reinforcement learning problem is challenging for several reasons, such as:
- The agent has to deal with uncertainty, as the environment may be stochastic (random) or partially observable (incomplete information).
- The agent has to balance between exploration and exploitation, as it has to try new actions to discover better ones, but also use the best actions that it has learned so far to maximize its reward.
- The agent has to cope with delayed rewards, as the consequences of its actions may not be immediate, but may depend on future actions and states.
- The agent has to handle large and complex state and action spaces, as the environment may have many possible states and actions, which may be continuous or high-dimensional.
These challenges make reinforcement learning a difficult but fascinating problem to solve, and require different types of algorithms and techniques.
In the next section, you will learn about the different types of reinforcement learning algorithms, and how they can be classified based on their properties and characteristics.
2.3. Types of Reinforcement Learning Algorithms
In this section, you will learn about the different types of reinforcement learning algorithms, and how they can be classified based on various criteria, such as:
- Model-based vs model-free: Model-based algorithms use a model of the environment, which is a function that predicts the next state and reward given the current state and action. Model-free algorithms do not use a model of the environment, but learn directly from experience.
- Value-based vs policy-based: Value-based algorithms learn a value function, which is a function that estimates the expected return for each state or state-action pair. Policy-based algorithms learn a policy function, which is a function that specifies the action to take for each state.
- On-policy vs off-policy: On-policy algorithms learn from the data generated by the current policy, which means that they explore and exploit at the same time. Off-policy algorithms learn from the data generated by a different policy, which means that they can separate exploration and exploitation.
Some of the most popular and widely used reinforcement learning algorithms are:
- Q-learning: A model-free, value-based, off-policy algorithm that learns a Q-function, which is a function that estimates the expected return for each state-action pair. Q-learning is one of the simplest but most powerful reinforcement learning algorithms, and it will be the main focus of this blog.
- SARSA: A model-free, value-based, on-policy algorithm that learns a Q-function, similar to Q-learning, but with a different update rule that takes into account the current policy.
- Monte Carlo methods: A model-free, value-based or policy-based, on-policy or off-policy algorithm that learns from complete episodes, rather than from individual steps. Monte Carlo methods use sampling and averaging to estimate the value function or the policy function.
- Temporal difference methods: A model-free, value-based or policy-based, on-policy or off-policy algorithm that learns from incomplete episodes, rather than from complete episodes. Temporal difference methods use bootstrapping and updating to estimate the value function or the policy function.
- Actor-critic methods: A model-free, policy-based, on-policy or off-policy algorithm that combines the advantages of value-based and policy-based methods. Actor-critic methods use two functions: an actor, which is a policy function that specifies the action to take for each state, and a critic, which is a value function that evaluates the action taken by the actor.
- Deep reinforcement learning methods: A model-free, value-based or policy-based, off-policy algorithm that uses deep neural networks to approximate the value function or the policy function. Deep reinforcement learning methods can handle large and complex state and action spaces, and have achieved remarkable results in various domains, such as Atari games, Go, and chess.
These are some of the most common types of reinforcement learning algorithms, but there are many more, and new ones are being developed and improved constantly. Reinforcement learning is a very active and exciting field of research, and there is still a lot to discover and learn.
In the next section, you will learn more about Q-learning, one of the most simple but powerful reinforcement learning algorithms, and how it works.
3. Q-Learning: A Simple but Powerful Algorithm
In this section, you will learn more about Q-learning, one of the most simple but powerful reinforcement learning algorithms. You will learn what Q-learning is, how it works, and what are its advantages and disadvantages.
What is Q-learning?
Q-learning is a model-free, value-based, off-policy reinforcement learning algorithm that learns a Q-function, which is a function that estimates the expected return for each state-action pair. Q-learning is based on the Bellman equation, which is a recursive equation that expresses the optimal value function in terms of the immediate reward and the discounted future value.
The idea behind Q-learning is to iteratively update the Q-function based on the agent’s experience, using the following formula:
$$Q(s, a) \leftarrow Q(s, a) + \alpha [r + \gamma \max_{a’} Q(s’, a’) – Q(s, a)]$$
where:
- $Q(s, a)$ is the current estimate of the Q-function for state $s$ and action $a$.
- $\alpha$ is the learning rate, which controls how much the Q-function is updated at each step.
- $r$ is the reward received by the agent after taking action $a$ in state $s$.
- $\gamma$ is the discount factor, which controls how much the agent values future rewards over immediate rewards.
- $\max_{a’} Q(s’, a’)$ is the maximum Q-value for the next state $s’$, which represents the best action that the agent can take in that state.
The update formula can be interpreted as follows: The new Q-value is equal to the old Q-value plus a correction term, which is proportional to the difference between the observed reward and the expected reward. The observed reward is the sum of the immediate reward and the discounted future reward, while the expected reward is the current Q-value. The correction term reduces the error between the Q-function and the optimal value function, and makes the Q-function converge to the optimal value function over time.
Q-learning is an off-policy algorithm, which means that it learns from the data generated by a different policy than the one it is learning. The policy that generates the data is called the behavior policy, and it is usually an exploratory policy, such as an $\epsilon$-greedy policy, which chooses a random action with a small probability $\epsilon$, and the best action according to the current Q-function with a high probability $1 – \epsilon$. The policy that Q-learning is learning is called the target policy, and it is usually a greedy policy, which always chooses the best action according to the current Q-function.
The advantage of using an off-policy algorithm is that it can separate exploration and exploitation, and learn from data that is not generated by the optimal policy. This allows Q-learning to be more efficient and robust than on-policy algorithms, which have to explore and exploit at the same time, and learn from data that is generated by the policy that they are learning.
How Q-learning Works
The basic steps of Q-learning are as follows:
- Initialize the Q-function arbitrarily, such as setting all Q-values to zero.
- Repeat for each episode (a sequence of actions and rewards that ends when the agent reaches a terminal state):
- Initialize the state $s$.
- Repeat for each step of the episode:
- Choose an action $a$ using the behavior policy, such as an $\epsilon$-greedy policy.
- Take action $a$ and observe the next state $s’$ and the reward $r$.
- Update the Q-function using the update formula.
- Set $s \leftarrow s’$.
- Until the state $s$ is terminal.
- Until the Q-function converges to the optimal value function.
The following pseudocode summarizes the Q-learning algorithm:
# Initialize the Q-function arbitrarily
Q = {}
for s in states:
for a in actions:
Q[s, a] = 0
# Repeat for each episode
for i in range(num_episodes):
# Initialize the state
s = initial_state()
# Repeat for each step of the episode
while not is_terminal(s):
# Choose an action using the behavior policy
a = epsilon_greedy(Q, s, epsilon)
# Take action and observe the next state and reward
s', r = take_action(a, s)
# Update the Q-function
Q[s, a] = Q[s, a] + alpha * (r + gamma * max Q[s', a'] - Q[s, a])
# Set the state to the next state
s = s'
# Until the state is terminal
# Until the Q-function converges
The following diagram illustrates the Q-learning algorithm:

Q-learning is a simple but powerful algorithm that can learn optimal policies for any MDP, given enough time and data. However, Q-learning also has some limitations and drawbacks, such as:
- Q-learning requires a discrete and finite state and action space, which may not be realistic or feasible for some problems.
- Q-learning may suffer from the curse of dimensionality, which means that the size of the Q-function grows exponentially with the number of states and actions, making it hard to store and update.
- Q-learning may be slow to converge or may not converge at all, especially if the learning rate is not chosen properly or if the environment is noisy or non-stationary.
- Q-learning may overestimate the Q-values, due to the max operator in the update formula, which can lead to suboptimal policies or instability.
These limitations and drawbacks motivate the development of more advanced and sophisticated reinforcement learning algorithms, such as deep Q-learning, which will be discussed in a later section.
In the next section, you will learn how to implement Q-learning with Keras and TensorFlow, and apply it to a simple but illustrative example.
3.1. What is Q-Learning?
Q-learning is a type of reinforcement learning algorithm that learns a Q-function, which is a function that estimates the expected return for each state-action pair. Q-learning is a model-free, value-based, off-policy algorithm, which means that it does not use a model of the environment, it learns a value function rather than a policy function, and it learns from the data generated by a different policy than the one it follows.
Q-learning was proposed by Christopher Watkins in his PhD thesis in 1989, and it is one of the simplest but most powerful reinforcement learning algorithms. Q-learning can solve any finite MDP, and it has been successfully applied to various domains, such as robotics, gaming, and control.
But how does Q-learning work? And what is the Q-function that it learns? Let’s find out.
What is the Q-function?
The Q-function, also known as the state-action value function, is a function that maps each state-action pair to a scalar value, which represents the expected return that the agent can obtain by taking that action in that state, and following a certain policy thereafter. The Q-function can be denoted as:
$$Q(s, a) = \mathbb{E}[R_t | s_t = s, a_t = a]$$
where $s$ is the state, $a$ is the action, $R_t$ is the return at time step $t$, and $\mathbb{E}$ is the expectation operator. The return $R_t$ is the sum of discounted rewards that the agent receives from time step $t$ onwards, and it can be defined as:
$$R_t = r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+3} + … = \sum_{k=0}^{\infty} \gamma^k r_{t+k+1}$$
where $r_{t+k+1}$ is the reward that the agent receives at time step $t+k+1$, and $\gamma$ is the discount factor, which is a number between 0 and 1 that determines how much the agent values future rewards compared to immediate rewards. A high value of $\gamma$ means that the agent cares more about the long-term consequences of its actions, while a low value of $\gamma$ means that the agent cares more about the short-term consequences of its actions.
The Q-function can be seen as a table, where each row corresponds to a state, and each column corresponds to an action. The value in each cell is the Q-value for that state-action pair. For example, consider the following gridworld environment, where the agent can move in four directions (up, down, left, or right), and the goal is to reach the terminal state marked with a star. The agent receives a reward of +1 for reaching the terminal state, and a reward of 0 for any other state. The discount factor is 0.9. The Q-function for this environment can be represented as:

The Q-function can help the agent to choose the best action in each state, by selecting the action that has the highest Q-value. This is called the greedy policy, and it can be defined as:
$$\pi(s) = \arg\max_a Q(s, a)$$
where $\pi(s)$ is the action that the greedy policy chooses in state $s$, and $\arg\max_a$ is the operator that returns the argument that maximizes the function. For example, in the gridworld environment, the greedy policy would choose to move right in the state (1, 1), since that action has the highest Q-value (0.81) in that state.
However, the greedy policy is not always the best policy, as it may be too short-sighted or too optimistic. For instance, in the gridworld environment, the greedy policy would choose to move up in the state (2, 2), since that action has the highest Q-value (0.59) in that state. But this action would lead the agent to a dead end, and prevent it from reaching the terminal state. A better policy would be to move left in the state (2, 2), even though that action has a lower Q-value (0.43) in that state. This action would allow the agent to explore more of the environment, and eventually find the optimal path to the terminal state.
Therefore, the agent needs to learn the optimal Q-function, which is the Q-function that corresponds to the optimal policy, which is the policy that maximizes the expected return for each state. The optimal Q-function can be denoted as:
$$Q^*(s, a) = \max_{\pi} Q^{\pi}(s, a)$$
where $Q^{\pi}(s, a)$ is the Q-function for policy $\pi$, and $\max_{\pi}$ is the operator that returns the maximum value over all possible policies. The optimal Q-function satisfies the following property, known as the Bellman optimality equation:
$$Q^*(s, a) = \mathbb{E}[r_{t+1} + \gamma \max_{a’} Q^*(s_{t+1}, a’) | s_t = s, a_t = a]$$
The Bellman optimality equation states that the optimal Q-value for a state-action pair is equal to the expected reward for taking that action in that state, plus the discounted expected reward for taking the best action in the next state. The Bellman optimality equation can be seen as a recursive relationship that defines the optimal Q-function in terms of itself.
The goal of Q-learning is to learn the optimal Q-function, or an approximation of it, by using the Bellman optimality equation as an update rule. But how does Q-learning do that? Let’s see in the next section.
3.2. How Q-Learning Works
Q-learning is a type of reinforcement learning algorithm that learns a Q-function, which is a function that estimates the expected return for each state-action pair. Q-learning uses the Bellman optimality equation as an update rule, which states that the optimal Q-value for a state-action pair is equal to the expected reward for taking that action in that state, plus the discounted expected reward for taking the best action in the next state.
But how does Q-learning use the Bellman optimality equation to learn the optimal Q-function? And what are the steps involved in the Q-learning algorithm? Let’s see.
The Q-learning Algorithm
The Q-learning algorithm is an iterative algorithm that updates the Q-function based on the agent’s experience. The Q-learning algorithm consists of the following steps:
- Initialize the Q-function arbitrarily, such as setting all Q-values to zero.
- Repeat for each episode (a sequence of actions and rewards that ends when the agent reaches a terminal state):
- Initialize the state.
- Repeat for each step of the episode:
- Choose an action using an exploration strategy, such as epsilon-greedy, which selects a random action with a probability of epsilon, and selects the greedy action (the action with the highest Q-value) with a probability of 1 – epsilon.
- Take the action and observe the next state and reward.
- Update the Q-value for the state-action pair using the Bellman optimality equation as follows:
- Set the state to the next state.
- Until the state is terminal.
- Until the Q-function converges to the optimal Q-function, or a sufficiently good approximation of it.
$$Q(s, a) \leftarrow Q(s, a) + \alpha [r + \gamma \max_{a’} Q(s’, a’) – Q(s, a)]$$
where $s$ is the current state, $a$ is the current action, $s’$ is the next state, $r$ is the reward, $\alpha$ is the learning rate (a number between 0 and 1 that determines how much the Q-value is updated), and $\gamma$ is the discount factor (a number between 0 and 1 that determines how much the agent values future rewards compared to immediate rewards).
The Q-learning algorithm can be summarized by the following pseudocode:
# Initialize Q-function arbitrarily
Q = zeros(states, actions)
# Loop for each episode
for episode in range(episodes):
# Initialize state
s = initial_state
# Loop for each step of the episode
while s is not terminal:
# Choose action using exploration strategy
a = choose_action(s, Q, epsilon)
# Take action and observe next state and reward
s', r = take_action(s, a)
# Update Q-value using Bellman optimality equation
Q[s, a] = Q[s, a] + alpha * (r + gamma * max(Q[s', :]) - Q[s, a])
# Set state to next state
s = s'
# End of episode
The Q-learning algorithm is a simple but powerful algorithm that can learn the optimal Q-function, or an approximation of it, by using the agent’s experience and the Bellman optimality equation. However, the Q-learning algorithm has some limitations and challenges, such as:
- The Q-learning algorithm requires a large amount of memory and computation, as it has to store and update a Q-value for each state-action pair. This can be problematic when the state and action spaces are large, continuous, or high-dimensional.
- The Q-learning algorithm can be slow to converge, as it has to explore a large and possibly unknown environment, and it may suffer from delayed rewards, meaning that the rewards for the agent’s actions may not be immediate, but may depend on future actions and states.
- The Q-learning algorithm can be affected by the exploration strategy, as it has to balance between exploration and exploitation, meaning that it has to try new actions to discover better ones, but also use the best actions that it has learned so far to maximize its reward. A common exploration strategy is epsilon-greedy, which selects a random action with a probability of epsilon, and selects the greedy action (the action with the highest Q-value) with a probability of 1 – epsilon. However, epsilon-greedy can be inefficient, as it may explore too much or too little, and it may not adapt to the changing environment.
These limitations and challenges motivate the need for more advanced and sophisticated reinforcement learning algorithms, such as deep Q-learning, which uses deep neural networks to approximate the Q-function, and policy gradient methods, which learn a policy function directly, rather than a value function. These algorithms will be discussed in the next sections.
3.3. Q-Learning Implementation with Keras and TensorFlow
In this section, you will learn how to implement Q-learning with Keras and TensorFlow, two of the most popular and powerful frameworks for deep learning. You will use Keras and TensorFlow to build a deep neural network that approximates the Q-function, and you will apply it to a simple reinforcement learning problem: the CartPole-v1 environment from OpenAI Gym.
The CartPole-v1 environment is a classic control problem, where the agent has to balance a pole on a cart by applying a force to the cart. The agent can choose between two actions: move the cart to the left or to the right. The state of the environment is a four-dimensional vector, consisting of the cart position, the cart velocity, the pole angle, and the pole angular velocity. The agent receives a reward of +1 for every time step that the pole remains upright, and the episode ends when the pole falls over or the cart moves out of the screen. The goal of the agent is to keep the pole balanced for as long as possible.
The CartPole-v1 environment can be illustrated by the following image:

To implement Q-learning with Keras and TensorFlow, you will need to follow these steps:
- Import the necessary libraries and modules, such as Keras, TensorFlow, OpenAI Gym, NumPy, and random.
- Create the CartPole-v1 environment using the gym.make() function, and get the number of states and actions using the env.observation_space.shape and env.action_space.n attributes.
- Build the Q-network using the Keras Sequential API, and add two dense layers with 32 and 16 units, respectively, and a final dense layer with the number of actions as the output. Use the ReLU activation function for the hidden layers, and the linear activation function for the output layer. Compile the Q-network using the Adam optimizer and the mean squared error loss function.
- Define the hyperparameters for the Q-learning algorithm, such as the number of episodes, the number of steps per episode, the discount factor, the learning rate, the exploration rate, and the exploration decay rate.
- Initialize the Q-network weights randomly, and create an empty list to store the rewards per episode.
- Loop for each episode:
- Reset the environment and get the initial state.
- Reset the reward and the step counter for the current episode.
- Loop for each step of the episode:
- Choose an action using the epsilon-greedy exploration strategy, which selects a random action with a probability of epsilon, and selects the greedy action (the action with the highest Q-value predicted by the Q-network) with a probability of 1 – epsilon.
- Take the action and observe the next state and reward.
- Store the transition (state, action, reward, next state) in a replay buffer, which is a data structure that stores the agent’s experience. You can use a deque (a double-ended queue) from the collections module, and set a maximum length to limit the size of the buffer.
- Sample a minibatch of transitions from the replay buffer, and use them to train the Q-network. To do this, you need to:
- Separate the states, actions, rewards, and next states from the minibatch, and convert them to NumPy arrays.
- Compute the target Q-values for the minibatch using the Bellman optimality equation as follows:
- Fit the Q-network on the states and target Q-values from the minibatch, using a single epoch and a fixed batch size. This will update the Q-network weights using gradient descent.
- Update the state, the reward, and the step counter.
- Reduce the exploration rate by multiplying it by the exploration decay rate, to decrease the amount of exploration as the agent learns.
- Add the reward for the current episode to the list of rewards per episode.
- Print the episode number, the reward, and the exploration rate.
- Plot the rewards per episode using matplotlib.pyplot, and observe how the agent’s performance improves over time.
$$y_i = r_i + \gamma \max_{a’} Q(s’_i, a’)$$
where $y_i$ is the target Q-value for the i-th transition, $r_i$ is the reward for the i-th transition, $\gamma$ is the discount factor, and $Q(s’_i, a’)$ is the Q-value predicted by the Q-network for the next state and action of the i-th transition. Note that you only need to update the Q-value for the action that was taken, and not for the other actions.
The Q-learning implementation with Keras and TensorFlow can be summarized by the following pseudocode:
# Import libraries and modules
import gym
import numpy as np
import random
from collections import deque
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
# Create the environment
env = gym.make('CartPole-v1')
# Get the number of states and actions
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
# Build the Q-network
model = Sequential()
model.add(Dense(32, input_dim=state_size, activation='relu'))
model.add(Dense(16, activation='relu'))
model.add(Dense(action_size, activation='linear'))
model.compile(loss='mse', optimizer=Adam(lr=0.001))
# Define the hyperparameters
episodes = 1000
steps = 200
gamma = 0.95
epsilon = 1.0
epsilon_min = 0.01
epsilon_decay = 0.995
batch_size = 32
# Initialize the Q-network weights randomly
model.summary()
# Create an empty list to store the rewards per episode
rewards = []
# Create a replay buffer
buffer = deque(maxlen=2000)
# Loop for each episode
for e in range(episodes):
# Reset the environment and get the initial state
state = env.reset()
state = np.reshape(state, [1, state_size])
# Reset the reward and the step counter for the current episode
total_reward = 0
step = 0
# Loop for each step of the episode
while step < steps:
# Choose an action using epsilon-greedy exploration strategy
if np.random.rand() < epsilon:
# Choose a random action
action = env.action_space.sample()
else:
# Choose the greedy action
action = np.argmax(model.predict(state))
# Take the action and observe the next state and reward
next_state, reward, done, info = env.step(action)
next_state = np.reshape(next_state, [1, state_size])
# Store the transition in the replay buffer
buffer.append((state, action, reward, next_state, done))
# Sample a minibatch of transitions from the replay buffer
if len(buffer) > batch_size:
minibatch = random.sample(buffer, batch_size)
# Separate the states, actions, rewards, and next states from the minibatch
states = np.array([t[0] for t in minibatch])
actions = np.array([t[1] for t in minibatch])
rewards = np.array([t[2] for t in minibatch])
next_states = np.array([t[3] for t in minibatch])
dones = np.array([t[4] for t in minibatch])
# Compute the target Q-values for the minibatch using the Bellman optimality equation
targets = rewards + gamma * np.amax(model.predict(next_states), axis=1)
targets = np.where(dones, rewards, targets)
# Fit the Q-network on the states and target Q-values from the minibatch
model.fit(states, targets, epochs=1, verbose=0, batch_size=batch_size)
# Update the state, the reward, and the step counter
state = next_state
total_reward += reward
step += 1
# Reduce the exploration rate
if epsilon > epsilon_min:
epsilon *= epsilon_decay
# If the episode is done, break the loop
if done:
break
# Add the reward for the current episode to the list of rewards per episode
rewards.append(total_reward)
# Print the episode number, the reward, and the exploration rate
print("Episode: {}, Reward: {}, Epsilon: {:.2f}".format(e, total_reward, epsilon))
# Plot the rewards per episode
plt.plot(rewards)
plt.xlabel('Episode')
plt.ylabel('Reward')
plt.show()
The Q-learning implementation with Keras and TensorFlow is a simple but effective way to apply Q-learning to
4. Advanced Topics in Reinforcement Learning and Q-Learning
In the previous sections, you learned the basics of reinforcement learning and Q-learning, and how to implement them with Keras and TensorFlow. You also learned how to apply Q-learning to a simple gridworld problem, and how to evaluate and visualize the results.
In this section, you will learn some advanced topics in reinforcement learning and Q-learning, that will help you improve your skills and knowledge, and tackle more challenging and realistic problems. You will learn about:
- Exploration vs exploitation: How to balance between trying new actions and using the best actions that you have learned so far, and how to use different exploration strategies, such as epsilon-greedy, softmax, and UCB.
- Deep Q-learning: How to use deep neural networks to approximate the Q-function, and how to overcome some of the challenges and limitations of Q-learning, such as overestimation bias, instability, and memory inefficiency.
- Policy gradient methods: How to use policy-based algorithms, that learn a policy function directly, rather than a value function, and how to use gradient ascent to optimize the policy function.
These topics are not exhaustive, but they will give you a glimpse of the vast and exciting field of reinforcement learning and Q-learning, and the many possibilities and opportunities that it offers.
Let’s start with the first topic: exploration vs exploitation.
4.1. Exploration vs Exploitation
One of the key challenges in reinforcement learning is the trade-off between exploration and exploitation. Exploration means trying new actions that you have not tried before, or that you are not sure about their outcomes. Exploitation means using the best actions that you have learned so far, or that you are confident about their outcomes.
Why is this trade-off important? Because you need both exploration and exploitation to learn effectively and efficiently. Exploration allows you to discover new and potentially better actions, and to avoid getting stuck in a local optimum. Exploitation allows you to use the knowledge that you have acquired, and to maximize your reward in the short term.
However, exploration and exploitation are conflicting goals. If you explore too much, you may waste time and resources on suboptimal actions, and miss the opportunity to use the best actions. If you exploit too much, you may miss the chance to find better actions, and settle for a suboptimal policy.
So, how can you balance between exploration and exploitation? There are different strategies that you can use, depending on the problem and the algorithm that you are using. In this section, you will learn about three common exploration strategies that you can use with Q-learning: epsilon-greedy, softmax, and UCB.
4.2. Deep Q-Learning
In the previous section, you learned about exploration vs exploitation, and how to use different strategies to balance between them. You also learned how to implement epsilon-greedy exploration with Q-learning, and how to tune the epsilon parameter to achieve better results.
In this section, you will learn about deep Q-learning, which is a variant of Q-learning that uses deep neural networks to approximate the Q-function. You will learn why deep Q-learning is useful, what are the challenges and limitations of Q-learning, and how to overcome them with deep Q-learning. You will also learn how to implement deep Q-learning with Keras and TensorFlow, and how to apply it to a more complex and realistic problem.
But first, let’s start with a simple question: What is deep Q-learning?
What is Deep Q-learning?
Deep Q-learning is a type of reinforcement learning algorithm that combines Q-learning with deep neural networks. Deep Q-learning was proposed by Mnih et al. (2015), who showed that it can achieve human-level performance on various Atari games, such as Breakout, Pong, and Space Invaders.
The main idea of deep Q-learning is to use a deep neural network, called a Q-network, to approximate the Q-function. The Q-network takes the state of the environment as input, and outputs the Q-values for each possible action. The Q-network is trained by minimizing the mean squared error between the predicted Q-values and the target Q-values, which are computed using the Bellman equation.
The following diagram illustrates the deep Q-learning algorithm:
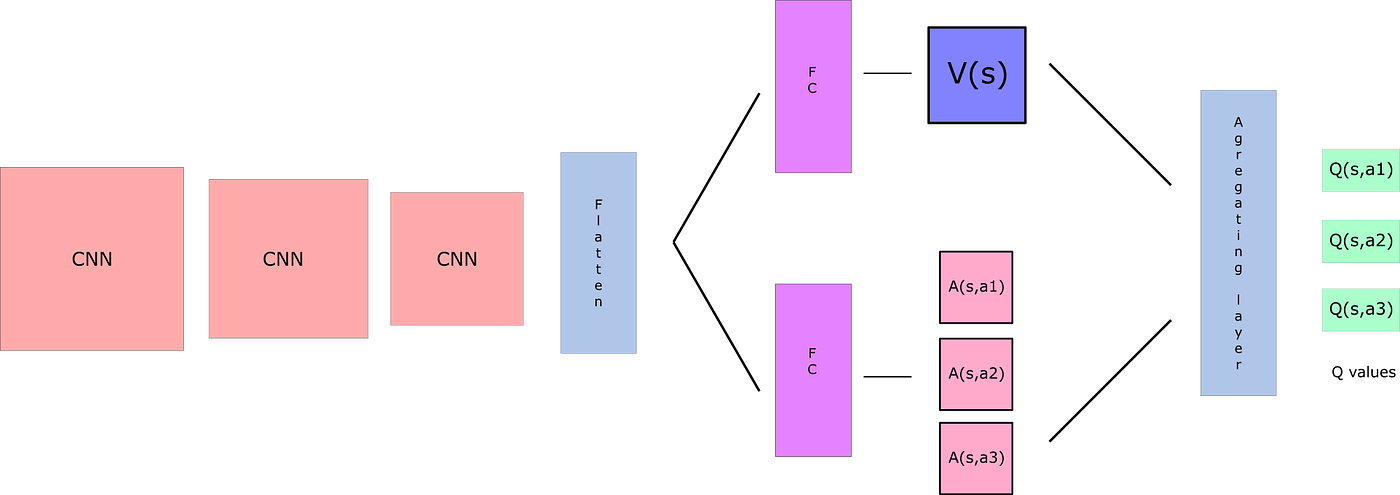
Deep Q-learning has several advantages over Q-learning, such as:
- It can handle large and complex state and action spaces, as it does not need to store and update a Q-table, but rather learns a Q-network that can generalize to unseen states.
- It can learn from high-dimensional and raw sensory inputs, such as images or sounds, as it can use convolutional neural networks or other types of neural networks to process them.
- It can learn from experience replay, which is a technique that stores the agent’s experiences in a memory buffer, and randomly samples mini-batches of experiences to train the Q-network. This reduces the correlation between consecutive experiences, and improves the data efficiency and stability of the algorithm.
However, deep Q-learning also has some challenges and limitations, such as:
- It may suffer from overestimation bias, which means that it may overestimate the Q-values of some actions, and thus select suboptimal actions. This is because the Q-network is trained to maximize the Q-values, and may learn to fit the noise or uncertainty in the data.
- It may be unstable or divergent, which means that it may fail to converge to a good policy, or even diverge to a worse policy. This is because the Q-network is trained with its own output as the target, and may propagate errors or fluctuations throughout the training process.
- It may be memory inefficient, which means that it may require a large amount of memory to store the experience replay buffer, and a long time to sample and train on the mini-batches of experiences.
These challenges and limitations can be addressed by using some extensions or improvements of deep Q-learning, such as:
- Double Q-learning: A technique that reduces the overestimation bias by using two Q-networks: one for selecting the best action, and one for evaluating the Q-value of that action. This decouples the action selection and evaluation, and makes the Q-value estimation more accurate.
- Dueling Q-learning: A technique that improves the stability and performance of the Q-network by using a dueling architecture, which consists of two streams: one for estimating the state value function, and one for estimating the state-dependent action advantage function. This allows the Q-network to learn the state value and the action advantage separately, and to combine them to obtain the Q-value.
- Prioritized experience replay: A technique that improves the memory efficiency and the learning speed of the Q-network by using a priority value for each experience, based on the magnitude of the temporal difference error. This allows the Q-network to sample more frequently the experiences that have a high priority value, and to learn more from them.
These are some of the most common extensions or improvements of deep Q-learning, but there are many more, and new ones are being developed and improved constantly. Deep Q-learning is a very active and exciting field of research, and there is still a lot to discover and learn.
In the next section, you will learn how to implement deep Q-learning with Keras and TensorFlow, and how to apply it to a more complex and realistic problem.
4.3. Policy Gradient Methods
In the previous section, you learned about deep Q-learning, which is a type of reinforcement learning algorithm that uses deep neural networks to approximate the Q-function. You also learned how to implement deep Q-learning with Keras and TensorFlow, and how to apply it to a more complex and realistic problem.
In this section, you will learn about policy gradient methods, which are another type of reinforcement learning algorithm that use deep neural networks to approximate the policy function. You will learn what policy gradient methods are, how they differ from value-based methods, and what are the advantages and challenges of policy gradient methods. You will also learn how to implement policy gradient methods with Keras and TensorFlow, and how to apply them to a different kind of problem.
But first, let’s start with a simple question: What are policy gradient methods?
What are Policy Gradient Methods?
Policy gradient methods are a type of reinforcement learning algorithm that use policy-based methods, rather than value-based methods. Policy-based methods learn a policy function directly, rather than a value function. A policy function is a function that specifies the action to take for each state, or the probability distribution over the actions for each state.
The main idea of policy gradient methods is to use a deep neural network, called a policy network, to approximate the policy function. The policy network takes the state of the environment as input, and outputs the action or the action probabilities for that state. The policy network is trained by using gradient ascent to maximize the expected return, which is the total amount of reward that the agent can expect to receive over time, or over an episode.
The following diagram illustrates the policy gradient method algorithm:

Policy gradient methods have several advantages over value-based methods, such as:
- They can handle continuous and high-dimensional action spaces, as they do not need to estimate the Q-values for each action, but rather output the action or the action probabilities directly.
- They can learn stochastic policies, which are policies that output a probability distribution over the actions, rather than a deterministic policy, which outputs a single action. This can be useful for exploration, or for problems that require mixed strategies.
- They can avoid the problem of overestimation bias, which is a problem that affects value-based methods, such as Q-learning, where they may overestimate the Q-values of some actions, and thus select suboptimal actions.
However, policy gradient methods also have some challenges and limitations, such as:
- They may suffer from high variance, which means that they may have large fluctuations in the policy network parameters and the expected return estimates, and thus require more samples and iterations to converge.
- They may converge to a local optimum, rather than a global optimum, which means that they may find a suboptimal policy, rather than the optimal policy, and get stuck there.
- They may have difficulty with delayed rewards, which means that they may have trouble attributing the reward to the correct actions, especially when the reward is sparse or delayed.
These challenges and limitations can be addressed by using some extensions or improvements of policy gradient methods, such as:
- Actor-critic methods: A technique that combines the advantages of policy-based and value-based methods, by using two networks: an actor, which is a policy network that specifies the action to take for each state, and a critic, which is a value network that evaluates the action taken by the actor.
- Advantage actor-critic (A2C): A technique that improves the actor-critic method by using the advantage function, which is a function that measures how much better an action is compared to the average action for a state, rather than the Q-function or the state value function.
- Proximal policy optimization (PPO): A technique that improves the policy gradient method by using a clipped objective function, which limits the change in the policy network parameters at each update, and prevents large deviations from the previous policy.
These are some of the most common extensions or improvements of policy gradient methods, but there are many more, and new ones are being developed and improved constantly. Policy gradient methods are a very active and exciting field of research, and there is still a lot to discover and learn.
In the next section, you will learn how to implement policy gradient methods with Keras and TensorFlow, and how to apply them to a different kind of problem.
5. Conclusion
In this blog, you have learned how to use reinforcement learning and Q-learning to train agents that can learn from their own actions and rewards. You have learned the basics of reinforcement learning, how Q-learning works, and how to implement it with Keras and TensorFlow. You have also learned some advanced topics in reinforcement learning and Q-learning, such as exploration vs exploitation, deep Q-learning, and policy gradient methods.
By following this blog, you have gained a solid understanding of reinforcement learning and Q-learning, and you have acquired the skills and knowledge to apply them to your own projects. You have also seen how to use Keras and TensorFlow, two of the most popular and powerful frameworks for deep learning, to build and train your reinforcement learning models.
Reinforcement learning and Q-learning are very exciting and powerful branches of machine learning, that have many applications in various domains, such as robotics, gaming, self-driving cars, and more. They can solve complex problems that require dynamic and adaptive behavior, and that are not easily solved by traditional methods.
However, reinforcement learning and Q-learning are also very challenging and fascinating problems to solve, and require different types of algorithms and techniques. There are many different types of reinforcement learning algorithms, and new ones are being developed and improved constantly. There is still a lot to discover and learn in this field, and there are many open questions and research directions.
We hope that this blog has sparked your interest and curiosity in reinforcement learning and Q-learning, and that you will continue to explore and learn more about them. We also hope that this blog has been useful and informative for you, and that you have enjoyed reading it and following it.
Thank you for reading this blog, and happy learning!




{kind=link}