
This blog teaches you how to use transformers and BERT, the state-of-the-art models for NLP, using PyTorch and HuggingFace libraries.
1. Introduction
Natural language processing (NLP) is a branch of artificial intelligence that deals with the interaction between computers and human languages. NLP aims to enable computers to understand, analyze, and generate natural language texts, such as articles, books, tweets, emails, and more.
However, natural language is complex and diverse, with many variations, ambiguities, and nuances. Therefore, traditional methods of NLP, such as rule-based systems or statistical models, often struggle to capture the full meaning and context of natural language texts.
This is where transformers and BERT come in. Transformers and BERT are two of the most advanced and powerful models for NLP, based on the concept of self-attention. Self-attention is a mechanism that allows the model to learn the relationships and dependencies between the words in a text, regardless of their distance or position.
Transformers and BERT have achieved state-of-the-art results on many NLP tasks, such as machine translation, text summarization, sentiment analysis, question answering, and more. They have also enabled the development of many other models and applications, such as GPT-3, T5, and HuggingFace.
In this tutorial, you will learn how to use PyTorch and HuggingFace to implement transformers and BERT for NLP. PyTorch is an open-source framework for deep learning, and HuggingFace is a library that provides easy access to pre-trained models and datasets for NLP. You will also learn the basics of transformers and BERT, how they work, and how to fine-tune them for your own NLP tasks.
By the end of this tutorial, you will have a solid understanding of transformers and BERT, and how to use them with PyTorch and HuggingFace. You will also be able to apply them to your own NLP projects and challenges.
Are you ready to dive into the world of transformers and BERT? Let’s get started!
2. What are transformers and why are they important for NLP?
Transformers are a type of neural network model that was introduced in 2017 by Vaswani et al. in their paper “Attention Is All You Need”. They were originally designed for machine translation, but they have since been applied to many other NLP tasks, such as text summarization, sentiment analysis, question answering, and more.
The main innovation of transformers is that they use self-attention to encode and decode the input and output sequences, instead of relying on recurrent or convolutional layers. Self-attention is a mechanism that allows the model to learn the relationships and dependencies between the words in a text, regardless of their distance or position. This enables the model to capture the long-range and global context of the text, as well as the local and syntactic features.
Another advantage of transformers is that they are highly parallelizable, meaning that they can process the entire input and output sequences at once, rather than sequentially. This makes them faster and more efficient than recurrent or convolutional models, especially for long sequences.
Transformers are important for NLP because they have achieved state-of-the-art results on many NLP benchmarks and tasks, such as the GLUE and SuperGLUE leaderboards, which measure the general language understanding ability of models. They have also enabled the development of many other models and applications, such as GPT-3, T5, and HuggingFace, which we will discuss later in this tutorial.
But how do transformers work exactly? And what is self-attention? To answer these questions, we need to look at the transformer architecture and the attention mechanism in more detail. Let’s do that in the next sections.
2.1. The transformer architecture
The transformer architecture consists of two main components: the encoder and the decoder. The encoder takes the input sequence, such as a sentence or a paragraph, and transforms it into a sequence of hidden states, which are vectors that represent the meaning and context of each word. The decoder takes the hidden states from the encoder and generates the output sequence, such as a translation or a summary.
Both the encoder and the decoder are composed of multiple layers, each of which has the same structure. Each layer consists of two sub-layers: a self-attention sub-layer and a feed-forward sub-layer. The self-attention sub-layer allows the model to learn the relationships and dependencies between the words in the sequence, while the feed-forward sub-layer applies a non-linear transformation to each word individually.
Between each sub-layer, there is a residual connection and a layer normalization operation. The residual connection adds the input of the sub-layer to its output, which helps to prevent the vanishing gradient problem and improve the learning speed. The layer normalization normalizes the output of the sub-layer to have zero mean and unit variance, which helps to stabilize the training and reduce the overfitting.
The following figure shows the schematic diagram of the transformer architecture, adapted from the original paper:
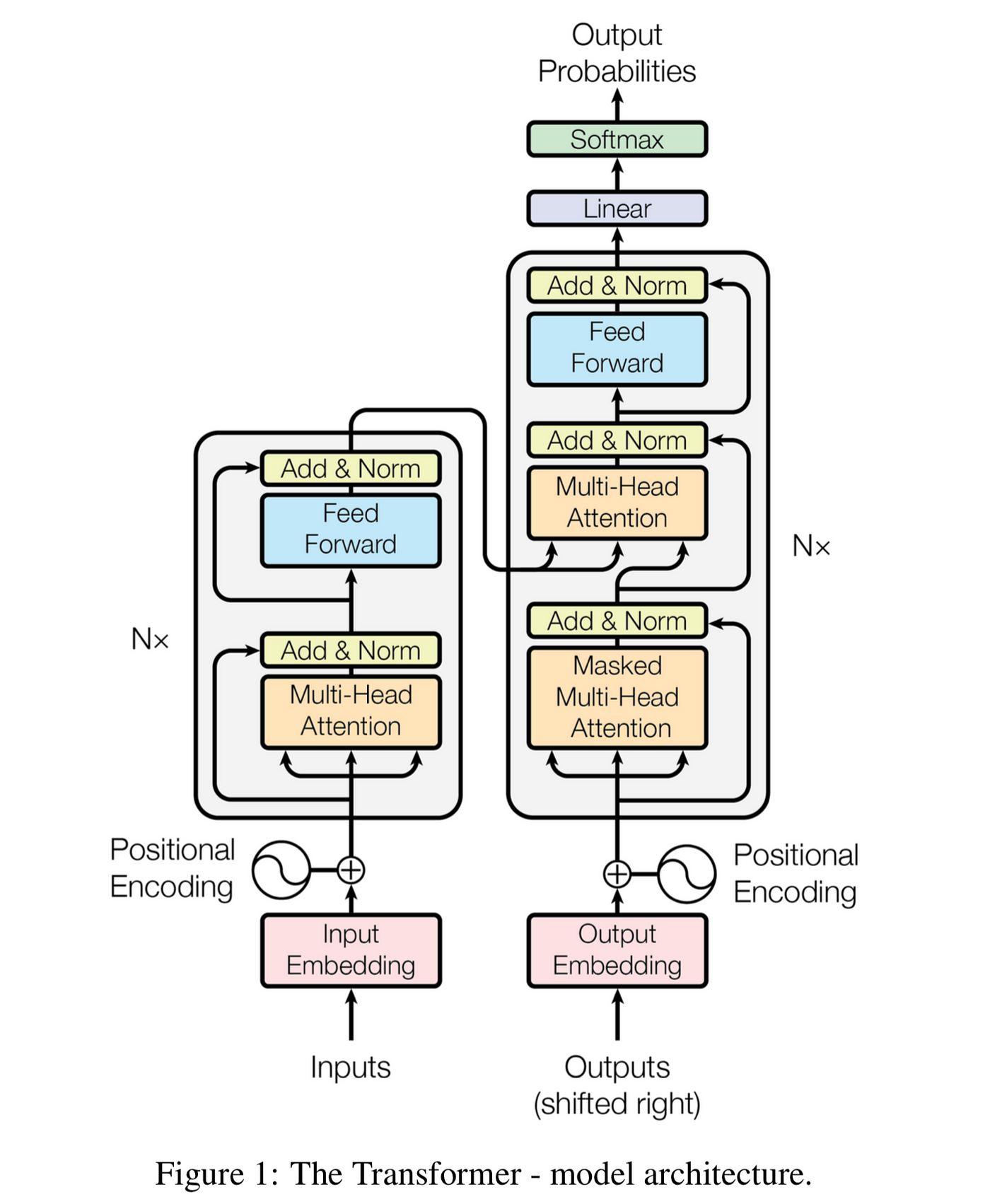
As you can see, the encoder has N layers, each of which has a self-attention sub-layer and a feed-forward sub-layer. The decoder also has N layers, but with an additional sub-layer that performs cross-attention between the hidden states of the encoder and the decoder. Cross-attention allows the decoder to focus on the relevant parts of the input sequence when generating the output sequence.
Now that you have a general idea of the transformer architecture, let’s dive deeper into the self-attention and cross-attention mechanisms, which are the core of the transformer model. We will do that in the next section.
2.2. The attention mechanism
The attention mechanism is a technique that allows the model to learn how to focus on the most relevant parts of the input and output sequences, and how to relate them to each other. There are two types of attention mechanisms: self-attention and cross-attention.
Self-attention is the process of computing the similarity between each pair of words in a sequence, and using these similarities to create a weighted representation of the sequence. For example, if the input sequence is “The cat sat on the mat”, the self-attention mechanism will calculate how much each word is related to every other word, and use these scores to create a new representation of the sentence that captures the meaning and context of each word.
Cross-attention is the process of computing the similarity between each word in the output sequence and each word in the input sequence, and using these similarities to create a weighted representation of the input sequence. For example, if the output sequence is “Le chat s’est assis sur le tapis”, which is the French translation of the input sequence, the cross-attention mechanism will calculate how much each word in the output sequence is related to each word in the input sequence, and use these scores to create a new representation of the input sequence that captures the relevant information for the translation task.
Both self-attention and cross-attention are implemented using a technique called scaled dot-product attention.
The scaled dot-product attention takes three inputs: the query, the key, and the value. The query, key, and value are all vectors that represent the words in the sequence. The query is the word that we want to focus on, the key is the word that we want to compare with the query, and the value is the word that we want to use to create the new representation.
The scaled dot-product attention computes the similarity between the query and the key by taking the dot product of them, and scaling it by the square root of the dimension of the key. This scaling factor helps to prevent the dot product from becoming too large and dominating the softmax function. The softmax function normalizes the similarity scores to have a sum of one, and converts them into probabilities. The probabilities are then multiplied by the value to obtain the weighted representation of the value. The weighted representations are then summed up to obtain the final output of the attention mechanism.
In an example, the query is the word “it”, the key and the value are the words in the sentence “Thinking machines are the future”, and the output is the new representation of the word “it”. The attention mechanism calculates the similarity between the query and each key, and uses these scores to create a weighted representation of each value. The weighted representations are then summed up to obtain the output, which is a vector that captures the meaning and context of the word “it” in the sentence.
However, a single scaled dot-product attention is not enough to capture the complex relationships and dependencies between the words in a sequence. Therefore, the transformer model uses a technique called multi-head attention, which is a combination of multiple scaled dot-product attentions, each with different query, key, and value vectors. The outputs of these attentions are then concatenated and projected to obtain the final output of the multi-head attention.
The multi-head attention allows the model to attend to different aspects of the input and output sequences, and learn different representations of them. For example, one attention head might focus on the syntactic structure of the sentence, while another might focus on the semantic meaning of the words.
Now that you have learned how the attention mechanism works, let’s move on to the next section, where we will introduce BERT, one of the most popular and powerful models based on the transformer architecture.
3. What is BERT and how does it work?
BERT stands for Bidirectional Encoder Representations from Transformers. It is a model that was introduced in 2018 by Devlin et al. in their paper “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”. BERT is based on the transformer architecture, but with some modifications and innovations.
The main idea of BERT is to pre-train a large transformer model on a large corpus of unlabeled text, using two unsupervised learning tasks: masked language modeling and next sentence prediction. Masked language modeling is a task where some words in a sentence are randomly masked (replaced with a special token), and the model has to predict the original words based on the context. Next sentence prediction is a task where the model has to predict whether two sentences are consecutive or not, based on the coherence and logic.
By pre-training on these tasks, BERT learns to encode the meaning and context of the words in a sentence, as well as the relationships and dependencies between the sentences. This allows BERT to generate rich and powerful representations of natural language texts, which can be used for various downstream NLP tasks, such as text classification, sentiment analysis, question answering, and more.
However, BERT is not a one-size-fits-all model. It needs to be fine-tuned for each specific NLP task, using a small amount of labeled data. Fine-tuning is the process of adjusting the parameters of the pre-trained model to optimize its performance on the target task. Fine-tuning BERT is relatively easy and fast, compared to training a model from scratch, because BERT already has a lot of general knowledge and skills from the pre-training process.
As you can see, BERT consists of a stack of transformer encoders, with a special token ([CLS]) at the beginning of the input sequence, and a special token ([SEP]) to separate the sentences. The output of the [CLS] token is used as the representation of the entire input sequence, which can be fed into a classifier layer for the downstream task. The output of each word token is used as the representation of the word, which can be fed into a softmax layer for the masked language modeling task. The output of the last encoder layer is also used as the input for the next sentence prediction task, which is a binary classification problem.
BERT has two variants: BERT-base and BERT-large. BERT-base has 12 encoder layers, 768 hidden units, and 12 attention heads, resulting in 110 million parameters. BERT-large has 24 encoder layers, 1024 hidden units, and 16 attention heads, resulting in 340 million parameters. BERT-large is more powerful and accurate than BERT-base, but also more computationally expensive and memory intensive.
BERT has been widely adopted and adapted by many researchers and practitioners, and has achieved state-of-the-art results on many NLP tasks and benchmarks. However, BERT is not perfect, and it has some limitations and challenges, such as the large size, the long inference time, the lack of interpretability, and the potential biases. These issues have motivated the development of many other models and applications, such as DistilBERT, RoBERTa, ALBERT, and HuggingFace, which we will discuss later in this tutorial.
But before we do that, let’s see how to use PyTorch and HuggingFace to implement transformers and BERT for NLP. We will do that in the next section.
3.1. The BERT pre-training process
The BERT pre-training process is the first step of training the BERT model, where the model learns general language skills and knowledge from a large corpus of unlabeled text. The BERT pre-training process consists of two main steps: data preparation and model training.
The data preparation step involves collecting and processing a large amount of text data from various sources, such as Wikipedia, books, news articles, web pages, and more. The text data is then tokenized, meaning that it is split into smaller units called tokens, which are the basic units of input for the BERT model. The tokens are then converted into numerical vectors, called embeddings, which represent the meaning and context of the tokens.
The model training step involves feeding the token embeddings to the BERT model, and training the model to perform two unsupervised learning tasks: masked language modeling and next sentence prediction. Masked language modeling is a task where some tokens in the input sequence are randomly masked (replaced with a special token), and the model has to predict the original tokens based on the context. Next sentence prediction is a task where the model has to predict whether two sentences are consecutive or not, based on the coherence and logic.
By training on these tasks, the BERT model learns to encode the meaning and context of the words in a sentence, as well as the relationships and dependencies between the sentences. This allows the BERT model to generate rich and powerful representations of natural language texts, which can be used for various downstream NLP tasks, such as text classification, sentiment analysis, question answering, and more.
The BERT pre-training process is computationally intensive and time-consuming, as it requires a large amount of text data and a large model size. Therefore, it is usually done only once, and the pre-trained model is then shared and reused by many researchers and practitioners. However, if you have a specific domain or task that requires a different or more specialized language model, you can also fine-tune the pre-trained model on your own data, which is the second step of training the BERT model. We will discuss how to do that in the next section.
3.2. The BERT fine-tuning process
The BERT fine-tuning process is the second step of training the BERT model, where the model is adapted to a specific NLP task, using a small amount of labeled data. The BERT fine-tuning process consists of two main steps: data preparation and model training.
The data preparation step involves collecting and processing a small amount of labeled data for the target task, such as text classification, sentiment analysis, question answering, and more. The labeled data is then tokenized, meaning that it is split into smaller units called tokens, which are the basic units of input for the BERT model. The tokens are then converted into numerical vectors, called embeddings, which represent the meaning and context of the tokens.
The model training step involves loading the pre-trained BERT model, and adding a task-specific layer on top of it, such as a classifier layer, a softmax layer, or a span extraction layer. The task-specific layer is initialized randomly, while the pre-trained BERT model is initialized with the parameters learned from the pre-training process. The model is then trained on the labeled data, using a learning rate scheduler and an optimizer, such as Adam. The training process adjusts the parameters of both the pre-trained BERT model and the task-specific layer, to optimize the performance on the target task.
The BERT fine-tuning process is relatively easy and fast, compared to training a model from scratch, because BERT already has a lot of general knowledge and skills from the pre-training process. However, the BERT fine-tuning process still requires some hyperparameter tuning and experimentation, such as choosing the number of epochs, the batch size, the learning rate, and the dropout rate. These hyperparameters can affect the accuracy and efficiency of the fine-tuned model, and they may vary depending on the task and the data.
The fine-tuned BERT model consists of the pre-trained BERT model and the task-specific layer. The input sequence is tokenized and embedded, and then fed to the BERT model, which generates a representation of the entire sequence and each word. The representation of the entire sequence is used as the input for the task-specific layer, which outputs a prediction for the target task.
Now that you have learned how the BERT fine-tuning process works, let’s see how to use PyTorch and HuggingFace to implement transformers and BERT for NLP. We will do that in the next section.
4. How to use PyTorch and HuggingFace to implement transformers and BERT
PyTorch and HuggingFace are two of the most popular and powerful frameworks for implementing transformers and BERT for NLP. PyTorch is an open-source framework for deep learning, which provides a flexible and intuitive way to build and train neural network models. HuggingFace is a library that provides easy access to pre-trained models and datasets for NLP, as well as tools and utilities to fine-tune and customize them.
In this section, we will show you how to use PyTorch and HuggingFace to implement transformers and BERT for NLP, using a simple text classification example. Text classification is a task where the model has to assign a label to a given text, such as positive or negative for sentiment analysis, or spam or ham for email filtering. We will use the IMDB movie reviews dataset, which contains 50,000 movie reviews labeled as positive or negative, as our data source.
The steps of implementing transformers and BERT for NLP using PyTorch and HuggingFace are as follows:
- Installing the required libraries
- Loading and processing the data
- Building and training the model
- Evaluating and testing the model
We will explain each step in detail in the following sections. Let’s start with installing the required libraries.
4.1. Installing the required libraries
To use PyTorch and HuggingFace to implement transformers and BERT for NLP, you need to install some libraries and packages on your machine. The libraries and packages that you need are:
- PyTorch: The framework for deep learning, which provides a flexible and intuitive way to build and train neural network models. You can install PyTorch using the following command:
pip install torch
- Transformers: The library from HuggingFace that provides easy access to pre-trained models and datasets for NLP, as well as tools and utilities to fine-tune and customize them. You can install Transformers using the following command:
pip install transformers
- Datasets: The library from HuggingFace that provides a simple and consistent way to load and process datasets for NLP, as well as metrics and evaluation tools. You can install Datasets using the following command:
pip install datasets
- NumPy: The library for scientific computing, which provides a fast and efficient way to manipulate arrays and matrices. You can install NumPy using the following command:
pip install numpy
- Pandas: The library for data analysis, which provides a convenient and powerful way to work with tabular data. You can install Pandas using the following command:
pip install pandas
- Matplotlib: The library for data visualization, which provides a simple and elegant way to create plots and graphs. You can install Matplotlib using the following command:
pip install matplotlib
Once you have installed these libraries and packages, you are ready to use PyTorch and HuggingFace to implement transformers and BERT for NLP. In the next section, we will show you how to load and process the data for the text classification example.
4.2. Loading and processing the data
The next step of implementing transformers and BERT for NLP using PyTorch and HuggingFace is to load and process the data for the text classification example. We will use the Datasets library from HuggingFace to load and process the IMDB movie reviews dataset, which contains 50,000 movie reviews labeled as positive or negative.
The Datasets library provides a simple and consistent way to load and process datasets for NLP, as well as metrics and evaluation tools. It also supports caching and streaming, which makes it efficient and scalable for large datasets. You can find more information about the Datasets library here.
To load the IMDB movie reviews dataset, you can use the following code:
from datasets import load_dataset
dataset = load_dataset("imdb")
This will download and cache the dataset on your machine, and return a DatasetDict object, which is a dictionary-like object that contains the different splits of the dataset, such as train, test, and validation. You can access the splits by using the keys of the DatasetDict, such as dataset["train"] or dataset["test"].
Each split of the dataset is a Dataset object, which is a table-like object that contains the columns and rows of the dataset. You can access the columns by using the dot notation, such as dataset["train"].text or dataset["train"].label. You can also access the rows by using the index notation, such as dataset["train"][0] or dataset["train"][10].
To process the data, you need to perform some steps, such as tokenizing the text, converting the labels to numbers, and splitting the data into batches. You can use the map method of the Dataset object to apply a function to each row of the dataset, and the set_format method to set the format of the dataset, such as the column names, the data types, and the output format. You can also use the shuffle and train_test_split methods to shuffle and split the dataset into train and test sets.
The following code shows an example of how to process the data using the Transformers library from HuggingFace, which provides a convenient way to tokenize the text and convert the labels to numbers:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
def encode(examples):
return tokenizer(examples["text"], truncation=True, padding="max_length")
dataset = dataset.map(encode, batched=True)
dataset = dataset.map(lambda examples: {"labels": examples["label"]}, batched=True)
dataset.set_format(type="torch", columns=["input_ids", "attention_mask", "labels"])
dataset = dataset.shuffle(seed=42)
dataset = dataset.train_test_split(test_size=0.2)
This will tokenize the text using the BERT tokenizer, truncate and pad the sequences to a maximum length of 512, convert the labels to numbers, set the format of the dataset to PyTorch tensors, shuffle the dataset with a random seed, and split the dataset into 80% train and 20% test sets.
Now that you have loaded and processed the data, you are ready to build and train the model using PyTorch and HuggingFace. We will show you how to do that in the next section.
4.3. Building and training the model
After loading and processing the data, the next step is to build and train the model using PyTorch and HuggingFace. The model that we will use is the BERTForSequenceClassification model, which is a pre-trained BERT model with a classifier layer on top. This model is suitable for text classification tasks, such as sentiment analysis, where the input is a single sentence and the output is a label.
The BERTForSequenceClassification model is available in the Transformers library from HuggingFace, which provides a convenient way to load and use pre-trained models for NLP. You can find more information about the Transformers library here.
To load the BERTForSequenceClassification model, you can use the following code:
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
This will download and cache the pre-trained BERT model with a classifier layer on top, and return a PyTorchModule object, which is a PyTorch module that wraps the model and its parameters. The model has two arguments: the name of the pre-trained model, and the number of labels for the classification task. In this case, we use the “bert-base-uncased” model, which is the base version of BERT with lowercased tokens, and we set the number of labels to 2, which corresponds to the positive and negative labels.
To train the model, you need to define some parameters, such as the learning rate, the batch size, the number of epochs, and the device. You can use the TrainingArguments class from the Transformers library to set these parameters, and the Trainer class to train the model. The Trainer class handles the training loop, the evaluation, the logging, and the saving of the model.
The following code shows an example of how to train the model using the Trainer class:
from transformers import TrainingArguments, Trainer training_args = TrainingArguments( output_dir="./results", learning_rate=2e-5, per_device_train_batch_size=16, per_device_eval_batch_size=16, num_train_epochs=3, logging_dir="./logs", ) trainer = Trainer( model=model, args=training_args, train_dataset=dataset["train"], eval_dataset=dataset["test"], ) trainer.train()
This will create a TrainingArguments object with the specified parameters, and a Trainer object with the model and the data. The trainer.train() method will start the training process, which will run for 3 epochs, and save the model and the logs in the output and logging directories.
Now that you have built and trained the model, you are ready to evaluate and test the model using PyTorch and HuggingFace. We will show you how to do that in the next section.
4.4. Evaluating and testing the model
The final step of implementing transformers and BERT for NLP using PyTorch and HuggingFace is to evaluate and test the model on the test set. The evaluation and testing process measures the performance of the model on unseen data, and provides some metrics and insights on how well the model can generalize and solve the task.
To evaluate and test the model, you can use the evaluate and predict methods of the Trainer class, which take the test dataset as an argument and return a dictionary of results. The evaluate method computes the loss and the metrics of the model on the test set, such as accuracy, precision, recall, and F1-score. The predict method generates the predictions and the labels of the model on the test set, which you can use to analyze the errors and the strengths of the model.
The following code shows an example of how to evaluate and test the model using the Trainer class:
evaluation_results = trainer.evaluate(dataset["test"]) print(evaluation_results) predictions, labels, _ = trainer.predict(dataset["test"]) print(predictions) print(labels)
This will print the evaluation results, such as the loss and the accuracy, and the predictions and the labels of the model on the test set. You can use these results to assess the quality and the reliability of the model, and to identify the areas where the model can be improved.
Congratulations! You have successfully implemented transformers and BERT for NLP using PyTorch and HuggingFace. You have learned how to load and process the data, how to build and train the model, and how to evaluate and test the model. You have also learned the basics of transformers and BERT, how they work, and why they are important for NLP.
In the next and final section, we will summarize the main points of this tutorial and provide some resources for further learning.
5. Conclusion
In this tutorial, you have learned how to use PyTorch and HuggingFace to implement transformers and BERT for NLP. You have also learned the basics of transformers and BERT, how they work, and why they are important for NLP.
Here are the main points that you have learned:
- Transformers are a type of neural network model that use self-attention to encode and decode the input and output sequences, instead of relying on recurrent or convolutional layers. Self-attention allows the model to learn the relationships and dependencies between the words in a text, regardless of their distance or position.
- BERT is a pre-trained transformer model that can be fine-tuned for various NLP tasks, such as text classification, text summarization, sentiment analysis, question answering, and more. BERT uses a masked language modeling and a next sentence prediction objectives to learn from a large corpus of unlabeled text.
- PyTorch is an open-source framework for deep learning, which provides a flexible and intuitive way to build and train neural network models.
- HuggingFace is a library that provides easy access to pre-trained models and datasets for NLP, as well as tools and utilities to fine-tune and customize them.
- Datasets is a library from HuggingFace that provides a simple and consistent way to load and process datasets for NLP, as well as metrics and evaluation tools.
We hope that you have enjoyed this tutorial and found it useful for your own NLP projects and challenges. If you want to learn more about transformers and BERT, PyTorch and HuggingFace, or NLP in general, here are some resources that you can check out:
- “Attention Is All You Need”: The original paper that introduced transformers.
- “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”: The original paper that introduced BERT.
- PyTorch website: The official website of PyTorch, where you can find the documentation, tutorials, examples, and community forums.
- HuggingFace website: The official website of HuggingFace, where you can find the documentation, tutorials, examples, and community forums.
- Datasets documentation: The official documentation of the Datasets library from HuggingFace.
- Stanford NLP Group: The website of the Stanford NLP Group, where you can find the latest research, courses, and projects on NLP.
Thank you for reading this tutorial and happy coding!



