
This blog introduces the concept and applications of generative adversarial networks (GANs), a powerful class of deep learning models that can generate realistic images and data samples.
1. Introduction
Have you ever wondered how some applications can generate realistic images of faces, landscapes, or artworks that do not exist in real life? Or how some models can create new data samples from a given distribution? These are some of the amazing capabilities of generative adversarial networks (GANs), a powerful class of deep learning models that can learn to mimic and generate complex data.
In this blog, you will learn the fundamentals of probabilistic deep learning and how to use GANs to create realistic images and data samples. You will also explore some of the applications, challenges, and limitations of GANs in various domains.
By the end of this blog, you will be able to:
- Explain the concept and components of GANs
- Implement a simple GAN in Python using TensorFlow and Keras
- Generate realistic images of handwritten digits using GANs
- Understand the advantages and disadvantages of GANs
- Explore some of the current and future applications of GANs
Ready to dive into the world of generative adversarial networks? Let’s get started!
2. What are Generative Adversarial Networks?
Generative adversarial networks (GANs) are a type of deep learning model that can learn to generate realistic and complex data from a given distribution, such as images, text, audio, or video. GANs were first introduced by Ian Goodfellow and his colleagues in 2014, and have since become one of the most popular and influential topics in machine learning research and applications.
But how do GANs work? What makes them so powerful and versatile? To answer these questions, we need to understand the main components and the underlying principle of GANs.
A GAN consists of two neural networks that compete with each other in a game-like scenario: the generator and the discriminator. The generator tries to create fake data that look like the real data, while the discriminator tries to distinguish between the real and the fake data. The generator and the discriminator are trained simultaneously, and the goal is to reach a state where the generator can fool the discriminator with high probability. This is called the adversarial loss, and it measures how well the generator and the discriminator are performing.
The following diagram illustrates the basic architecture and the training process of a GAN:
In the next sections, we will dive deeper into the details of the generator, the discriminator, and the adversarial loss, and see how they work together to create realistic and diverse data samples.
2.1. The Generator
The generator is the neural network that creates the fake data samples in a GAN. The generator takes a random noise vector as input and transforms it into a realistic data sample, such as an image, using a series of convolutional or deconvolutional layers. The generator tries to fool the discriminator by producing data samples that are indistinguishable from the real ones.
The following code snippet shows how to define a simple generator network in Python using TensorFlow and Keras. The generator takes a 100-dimensional noise vector as input and outputs a 28×28 grayscale image of a handwritten digit. The generator uses four deconvolutional layers with batch normalization and LeakyReLU activation functions to generate the image.
# Import TensorFlow and Keras import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers # Define the generator network def make_generator_model(): # Input layer: a 100-dimensional noise vector noise = layers.Input(shape=(100,)) # First deconvolutional layer: 7x7x256 feature maps x = layers.Dense(7*7*256, use_bias=False)(noise) x = layers.BatchNormalization()(x) x = layers.LeakyReLU()(x) x = layers.Reshape((7, 7, 256))(x) # Second deconvolutional layer: 14x14x128 feature maps x = layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False)(x) x = layers.BatchNormalization()(x) x = layers.LeakyReLU()(x) # Third deconvolutional layer: 14x14x64 feature maps x = layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False)(x) x = layers.BatchNormalization()(x) x = layers.LeakyReLU()(x) # Fourth deconvolutional layer: 28x28x1 feature maps x = layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh')(x) # Output layer: a 28x28 grayscale image image = layers.Reshape((28, 28))(x) # Create the generator model model = keras.Model(inputs=noise, outputs=image) return model
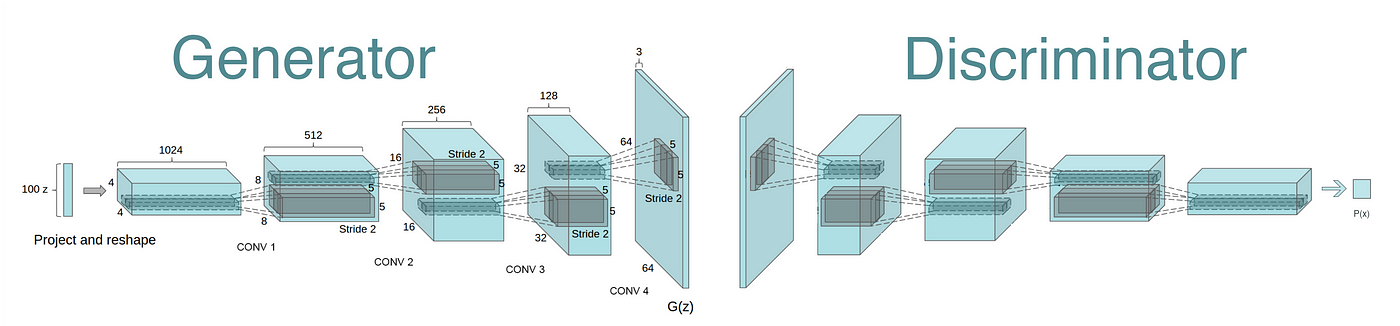
The generator network can be visualized as follows:
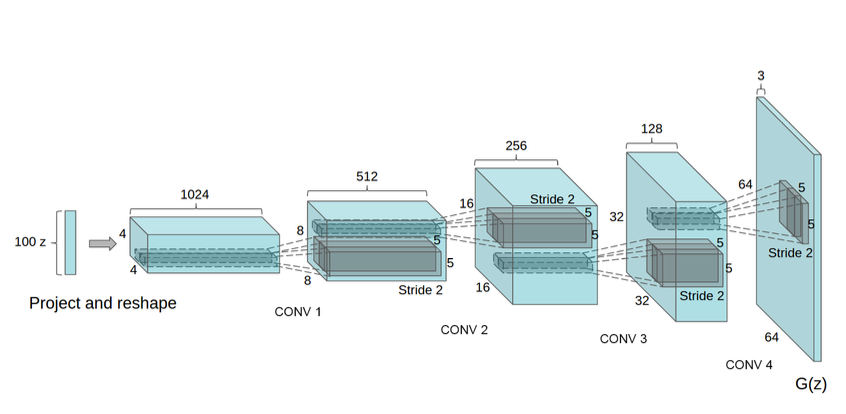
Source: https://towardsdatascience.com/gan-by-example-using-keras-on-tensorflow-backend-1a6d515a60d0
The generator network is not trained by itself, but together with the discriminator network in a GAN. The generator learns to improve its output quality and diversity by minimizing the adversarial loss, which we will discuss in the next section.
2.2. The Discriminator
The discriminator is the neural network that evaluates the data samples in a GAN. The discriminator takes a data sample as input, either real or fake, and outputs a probability score indicating how likely it is that the sample is real. The discriminator tries to catch the generator by rejecting the fake samples and accepting the real ones.
The following code snippet shows how to define a simple discriminator network in Python using TensorFlow and Keras. The discriminator takes a 28×28 grayscale image of a handwritten digit as input and outputs a scalar value between 0 and 1. The discriminator uses four convolutional layers with batch normalization and LeakyReLU activation functions to process the image.
# Import TensorFlow and Keras import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers # Define the discriminator network def make_discriminator_model(): # Input layer: a 28x28 grayscale image image = layers.Input(shape=(28, 28, 1)) # First convolutional layer: 14x14x64 feature maps x = layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same')(image) x = layers.BatchNormalization()(x) x = layers.LeakyReLU()(x) # Second convolutional layer: 7x7x128 feature maps x = layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same')(x) x = layers.BatchNormalization()(x) x = layers.LeakyReLU()(x) # Third convolutional layer: 4x4x256 feature maps x = layers.Conv2D(256, (5, 5), strides=(2, 2), padding='same')(x) x = layers.BatchNormalization()(x) x = layers.LeakyReLU()(x) # Fourth convolutional layer: 4x4x512 feature maps x = layers.Conv2D(512, (5, 5), strides=(1, 1), padding='same')(x) x = layers.BatchNormalization()(x) x = layers.LeakyReLU()(x) # Output layer: a scalar value between 0 and 1 x = layers.Flatten()(x) score = layers.Dense(1, activation='sigmoid')(x) # Create the discriminator model model = keras.Model(inputs=image, outputs=score) return model
The discriminator network is not trained by itself, but together with the generator network in a GAN. The discriminator learns to improve its accuracy and robustness by maximizing the adversarial loss, which we will discuss in the next section.
2.3. The Adversarial Loss
The adversarial loss is the objective function that drives the training of a GAN. The adversarial loss measures how well the generator and the discriminator are performing in their respective tasks. The adversarial loss is composed of two terms: the generator loss and the discriminator loss.
The generator loss is the term that the generator tries to minimize. The generator loss is defined as the negative log-likelihood of the discriminator’s output given the fake samples generated by the generator. The generator loss can be interpreted as the generator’s ability to fool the discriminator. A lower generator loss means that the generator can produce more realistic and diverse samples that the discriminator cannot reject.
The discriminator loss is the term that the discriminator tries to maximize. The discriminator loss is defined as the sum of the negative log-likelihoods of the discriminator’s output given the real samples and the fake samples. The discriminator loss can be interpreted as the discriminator’s accuracy and robustness. A higher discriminator loss means that the discriminator can correctly classify the real and the fake samples with high confidence.
The following code snippet shows how to define the adversarial loss function in Python using TensorFlow and Keras. The adversarial loss function takes the real samples, the fake samples, and the discriminator’s output as inputs and returns the generator loss and the discriminator loss as outputs. The adversarial loss function uses the binary cross-entropy as the log-likelihood function.
# Import TensorFlow and Keras import tensorflow as tf from tensorflow import keras from tensorflow.keras import losses # Define the adversarial loss function def adversarial_loss(real_samples, fake_samples, discriminator_output): # Define the binary cross-entropy as the log-likelihood function bce = losses.BinaryCrossentropy(from_logits=True) # Compute the generator loss generator_loss = bce(tf.ones_like(discriminator_output), discriminator_output) # Compute the discriminator loss discriminator_loss = bce(tf.ones_like(real_samples), real_samples) + bce(tf.zeros_like(fake_samples), fake_samples) # Return the generator loss and the discriminator loss return generator_loss, discriminator_loss
The adversarial loss function is used to update the parameters of the generator and the discriminator networks in a GAN. The generator and the discriminator are trained alternately, with the generator trying to minimize the adversarial loss and the discriminator trying to maximize it. The training process stops when the generator and the discriminator reach an equilibrium state, where the generator can generate realistic samples and the discriminator cannot tell them apart from the real ones.
3. Applications of Generative Adversarial Networks
Generative adversarial networks (GANs) have been applied to a wide range of domains and tasks, demonstrating their versatility and creativity. In this section, we will explore some of the most popular and impressive applications of GANs, focusing on three areas: image generation, data augmentation, and style transfer.
3.1. Image Generation
Image generation is one of the most common and impressive applications of GANs. Image generation is the task of creating realistic images from scratch, such as faces, animals, landscapes, or artworks. Image generation can be used for various purposes, such as entertainment, education, research, or art.
One of the most famous examples of image generation using GANs is This Person Does Not Exist, a website that generates realistic and diverse faces of people who do not exist in real life. The website uses a GAN model called StyleGAN, which can control various aspects of the generated images, such as the pose, expression, hair, skin, age, and gender. The website updates the images every time the page is refreshed, showing the endless possibilities of GANs.
Another example of image generation using GANs is DeepArt, a website that allows users to create artistic images based on their own photos. The website uses a GAN model called Neural Style Transfer, which can transfer the style of one image to another, such as applying the style of a famous painting to a photo. The website lets users upload their own photos and choose from a variety of styles, such as Van Gogh, Picasso, or Monet.
These are just some of the examples of image generation using GANs. There are many more applications and variations of GANs for image generation, such as super-resolution, image inpainting, image-to-image translation, and text-to-image synthesis. Image generation using GANs is a fascinating and active field of research and development, with new models and techniques being proposed and improved constantly.
3.1. Image Generation
One of the most impressive and popular applications of GANs is image generation. Image generation is the task of creating realistic images from a given input, such as a text description, a sketch, a noise vector, or another image. Image generation can have many uses, such as art, entertainment, education, and research.
How can GANs generate images that look like the real ones? The key idea is to train the generator to produce images that can fool the discriminator, which is trained on real images from a specific domain, such as faces, animals, or landscapes. The generator takes a random noise vector as input and transforms it into an image, while the discriminator tries to classify the image as real or fake. The generator and the discriminator are trained in an adversarial manner, until the generator can produce images that are indistinguishable from the real ones by the discriminator.
Here is an example of how a GAN can generate realistic images of faces from random noise vectors:

Source: https://towardsdatascience.com/generative-adversarial-networks-gans-a-beginners-guide-5b38eceece24
As you can see, the generator starts with low-quality and blurry images, but gradually improves its output as it learns from the discriminator’s feedback. The final images are very realistic and diverse, and they do not exist in the real world.
In the next section, we will see how to implement a simple GAN in Python using TensorFlow and Keras, and how to use it to generate images of handwritten digits.
3.2. Data Augmentation
Data augmentation is another important application of GANs, especially in domains where data is scarce or expensive to obtain. Data augmentation is the process of creating new data samples from existing ones, by applying some transformations or variations, such as cropping, rotating, flipping, scaling, or adding noise. Data augmentation can help improve the performance and generalization of machine learning models, by increasing the diversity and size of the training data.
However, traditional data augmentation methods have some limitations, such as being domain-specific, requiring manual tuning, and producing low-quality or unrealistic samples. GANs can overcome these limitations, by learning to generate new data samples that are realistic, diverse, and consistent with the original data distribution. GANs can also create data samples that are not possible to obtain by conventional methods, such as images with different poses, expressions, or backgrounds.
As you can see, the GAN can create realistic and diverse images of faces, that can help improve the face recognition model’s accuracy and robustness.
In the next section, we will see another application of GANs, which is style transfer, where we can change the style or appearance of an image while preserving its content.
3.3. Style Transfer
Style transfer is another fascinating application of GANs, where we can change the style or appearance of an image while preserving its content. Style transfer can be used for artistic purposes, such as creating new artworks from existing ones, or for practical purposes, such as enhancing the quality or resolution of an image.
How can GANs perform style transfer? The main idea is to train the generator to transform an image from one domain to another, such as from a photo to a painting, or from a low-resolution image to a high-resolution image. The generator takes an image as input and outputs a stylized image, while the discriminator tries to classify the output image as real or fake. The generator and the discriminator are trained in an adversarial manner, until the generator can produce images that are realistic and consistent with the target domain.
4. Challenges and Limitations of Generative Adversarial Networks
GANs are powerful and versatile models, but they are not without challenges and limitations. In this section, we will discuss some of the common difficulties and drawbacks of GANs, and how to overcome them.
One of the main challenges of GANs is mode collapse, which occurs when the generator produces a limited variety of samples, or even the same sample, regardless of the input noise. Mode collapse happens when the generator finds a sample that can fool the discriminator easily, and then stops exploring other samples. Mode collapse reduces the diversity and quality of the generated data, and makes the GAN fail to capture the complexity of the real data distribution.
There are several ways to prevent or mitigate mode collapse, such as:
- Using different architectures or loss functions for the generator and the discriminator, such as Wasserstein GANs or Least Squares GANs
- Adding noise or regularization to the discriminator’s output, such as label smoothing or dropout
- Using multiple generators or discriminators, such as Mixture of Gaussians GANs or Multi-Discriminator GANs
- Using additional information or constraints, such as conditional GANs or cycle-consistent GANs
Another challenge of GANs is training instability, which occurs when the generator and the discriminator do not converge to a stable equilibrium, or oscillate between different states. Training instability happens when the generator and the discriminator have different learning rates, capacities, or objectives, and they cannot balance each other. Training instability leads to poor and inconsistent results, and makes the GAN hard to train and evaluate.
There are several ways to improve the stability and convergence of GANs, such as:
- Using gradient clipping or normalization to prevent gradient explosion or vanishing
- Using batch normalization or layer normalization to reduce internal covariate shift and improve generalization
- Using spectral normalization or weight clipping to limit the Lipschitz constant and smooth the discriminator’s output
- Using curriculum learning or self-attention to gradually increase the difficulty and focus of the generator and the discriminator
A final challenge of GANs is evaluation metrics, which are used to measure the performance and quality of the generated data. Evaluation metrics are important for comparing different GANs, tuning hyperparameters, and monitoring progress. However, evaluation metrics for GANs are not well-defined or agreed upon, and they often depend on the specific domain and task. Evaluation metrics for GANs can be divided into two categories: quantitative and qualitative.
Quantitative metrics are numerical scores that reflect some aspects of the generated data, such as realism, diversity, fidelity, or similarity. Some examples of quantitative metrics are:
- Inception score, which measures how realistic and diverse the generated images are, based on a pretrained classifier
- Fréchet inception distance, which measures how similar the generated images are to the real images, based on a pretrained feature extractor
- Structural similarity index, which measures how faithful the generated images are to the original images, based on pixel-wise comparisons
- Word error rate, which measures how accurate the generated text is, based on edit distance
Qualitative metrics are visual or auditory inspections that assess the quality and diversity of the generated data, based on human perception and judgment. Some examples of qualitative metrics are:
- Pairwise comparison, which asks human evaluators to compare two generated samples and choose the better one
- Preference score, which asks human evaluators to rate the generated samples on a scale of preference
- Turing test, which asks human evaluators to distinguish between real and generated samples
- User study, which asks human evaluators to perform a task or answer a question using the generated samples
In the next and final section, we will conclude this blog and summarize the main points.
4.1. Mode Collapse
One of the major challenges of training GANs is the problem of mode collapse. Mode collapse occurs when the generator produces a limited variety of data samples, instead of capturing the diversity of the real data distribution. This happens because the generator finds a few data samples that can fool the discriminator easily, and then keeps generating similar or identical samples. As a result, the generator fails to learn the true data distribution, and the quality and diversity of the generated data suffer.
But why does mode collapse happen? And how can we prevent it? To answer these questions, we need to understand the concept of Nash equilibrium. Nash equilibrium is a state where no player in a game can improve their outcome by changing their strategy, assuming that the other players keep their strategies fixed. In other words, Nash equilibrium is a stable state where no one has an incentive to deviate from their current strategy.
In the context of GANs, Nash equilibrium is a state where the generator and the discriminator are perfectly balanced, and neither of them can improve their performance by changing their parameters. Ideally, this state should correspond to the generator learning the true data distribution, and the discriminator being unable to distinguish between the real and the fake data. However, in practice, there may be multiple Nash equilibria, some of which may correspond to mode collapse. For example, if the generator produces a single data sample that can fool the discriminator, and the discriminator assigns a high probability to that sample, then both networks are in a Nash equilibrium, but not in the desired one.
Therefore, to avoid mode collapse, we need to ensure that the generator and the discriminator do not converge to a bad Nash equilibrium, but rather to a good one. There are several techniques that can help with this, such as:
- Adding noise or regularization to the generator or the discriminator, to prevent them from overfitting or memorizing the data samples.
- Using different architectures or loss functions for the generator or the discriminator, to make the optimization problem more challenging or diverse.
- Using multiple generators or discriminators, to increase the variety and complexity of the generated data samples.
In the next section, we will discuss another challenge of training GANs: training instability.
4.2. Training Instability
Another challenge of training GANs is the problem of training instability. Training instability refers to the difficulty of finding a good balance between the generator and the discriminator during the training process. If the generator or the discriminator becomes too strong or too weak, the training may not converge or may oscillate between different states. This can lead to poor quality or diversity of the generated data, or even to the failure of the training.
But why does training instability happen? And how can we overcome it? To answer these questions, we need to understand the concept of gradient descent. Gradient descent is a common optimization technique that updates the parameters of a neural network by moving them in the opposite direction of the gradient of the loss function. In other words, gradient descent tries to find the minimum of the loss function by following the steepest downhill direction.
In the context of GANs, gradient descent is used to update the parameters of both the generator and the discriminator. However, since the generator and the discriminator have opposite objectives, their gradients are also opposite. This means that when one network improves, the other network worsens, and vice versa. This creates a dynamic and non-stationary optimization problem, where the loss function and the gradient change constantly. As a result, the training may become unstable and unpredictable.
Therefore, to achieve training stability, we need to ensure that the generator and the discriminator are updated in a balanced and coordinated way. There are several techniques that can help with this, such as:
- Using a suitable learning rate and batch size, to avoid large or noisy updates that may disrupt the training.
- Using different optimizers or schedules for the generator or the discriminator, to control the speed or frequency of their updates.
- Using gradient clipping or normalization, to prevent the gradients from becoming too large or too small.
In the next section, we will discuss another challenge of training GANs: evaluation metrics.
4.3. Evaluation Metrics
A final challenge of training GANs is the problem of evaluation metrics. Evaluation metrics are used to measure the quality and diversity of the generated data, and to compare the performance of different GAN models. However, unlike other supervised or unsupervised learning tasks, there is no clear and objective way to evaluate the output of GANs. This is because the generated data are not labeled, and the true data distribution is unknown.
But why are evaluation metrics important? And how can we design them? To answer these questions, we need to understand the concept of fidelity and diversity. Fidelity is the degree to which the generated data resemble the real data, and diversity is the degree to which the generated data cover the variety of the real data. Ideally, we want GANs to produce high-fidelity and high-diversity data, that can fool human observers and capture the richness of the real data.
However, measuring fidelity and diversity is not easy, as they depend on subjective and context-specific criteria. For example, what makes an image realistic or diverse may vary depending on the domain, the task, or the human perception. Therefore, there is no single or universal metric that can capture these aspects. Instead, there are several metrics that can approximate them, such as:
- Inception Score (IS): This metric uses a pretrained classifier to measure how well the generated images match the expected labels, and how diverse the labels are. A higher IS indicates higher fidelity and diversity.
- Fréchet Inception Distance (FID): This metric uses a pretrained feature extractor to measure the distance between the feature distributions of the real and the generated images. A lower FID indicates higher fidelity.
- Precision and Recall (PR): These metrics use a pretrained feature extractor to measure how many of the generated images are similar to the real images (precision), and how many of the real images are similar to the generated images (recall). Higher precision and recall indicate higher fidelity and diversity.
These metrics are some of the most commonly used ones, but they are not perfect or comprehensive. They have some limitations and assumptions, such as relying on pretrained models, being sensitive to hyperparameters, or ignoring the semantic or structural aspects of the data. Therefore, it is important to use multiple metrics and complementary methods, such as human evaluation or visualization, to assess the performance of GANs.
In the next and final section, we will conclude this blog and summarize the main points.
5. Conclusion
In this blog, you have learned the fundamentals of probabilistic deep learning and how to use generative adversarial networks (GANs) to create realistic images and data samples. You have also explored some of the applications, challenges, and limitations of GANs in various domains.
Here are the main points that you have learned:
- GANs are a type of deep learning model that can learn to generate realistic and complex data from a given distribution, such as images, text, audio, or video.
- GANs consist of two neural networks that compete with each other in a game-like scenario: the generator and the discriminator. The generator tries to create fake data that look like the real data, while the discriminator tries to distinguish between the real and the fake data.
- The generator and the discriminator are trained simultaneously, and the goal is to reach a state where the generator can fool the discriminator with high probability. This is called the adversarial loss, and it measures how well the generator and the discriminator are performing.
- GANs have many applications in various domains, such as image generation, data augmentation, style transfer, and more. GANs can create realistic and diverse data samples that can be used for various purposes, such as enhancing existing data, creating new data, or transferring data across domains.
- GANs also have some challenges and limitations, such as mode collapse, training instability, and evaluation metrics. Mode collapse occurs when the generator produces a limited variety of data samples, instead of capturing the diversity of the real data distribution. Training instability refers to the difficulty of finding a good balance between the generator and the discriminator during the training process. Evaluation metrics are used to measure the quality and diversity of the generated data, and to compare the performance of different GAN models. However, there is no clear and objective way to evaluate the output of GANs.
We hope that this blog has given you a comprehensive and intuitive understanding of GANs, and inspired you to explore more about this fascinating topic. If you want to learn more about GANs, you can check out some of the following resources:
- Generative Adversarial Networks: The original paper by Ian Goodfellow and his colleagues that introduced GANs.
- GANs: An Introduction: A Google Developers tutorial that covers the basics and the applications of GANs.
- The GAN Zoo: A list of GAN variants and papers that show the diversity and the evolution of GANs.
- How to Code a GAN from Scratch: A practical tutorial that shows how to implement a simple GAN in Python using TensorFlow and Keras.
Thank you for reading this blog, and we hope you enjoyed it. Feel free to leave your comments or questions below, and we will try to answer them as soon as possible. Happy learning!



